

Recast官网
将您想阅读的文章转化为丰富的音频摘要

Recast简介
需求人群:
适用于需要大量阅读文章的工作场景,也适用于休闲时间想要了解最新资讯的用户。
产品特色:
将文章转化为音频摘要
自动摘要和语音合成技术
多种定价选项
节省时间,提高阅读效率
Recast官网入口网址
https://www.letsrecast.ai
小编发现Recast网站非常受用户欢迎,请访问Recast网址入口试用。
将您想阅读的文章转化为丰富的音频摘要
适用于需要大量阅读文章的工作场景,也适用于休闲时间想要了解最新资讯的用户。
将文章转化为音频摘要
自动摘要和语音合成技术
多种定价选项
节省时间,提高阅读效率
https://www.letsrecast.ai
小编发现Recast网站非常受用户欢迎,请访问Recast网址入口试用。

用于视觉合成的统一3D Transformer流水线

“适用于研究人员和开发者,用于视觉合成、图像和视频处理等领域。”
使用NUWA模型生成新的图像或视频内容
利用NUWA-Infinity进行无限视觉合成
通过NUWA-LIP进行语言引导的图像修复
视觉数据生成与操纵
多模态预训练
无限视觉合成
语言引导的图像修复
自监督学习3D摄影视频
长视频生成
https://github.com/microsoft/NUWA
小编发现NUWA网站非常受用户欢迎,请访问NUWA网址入口试用。
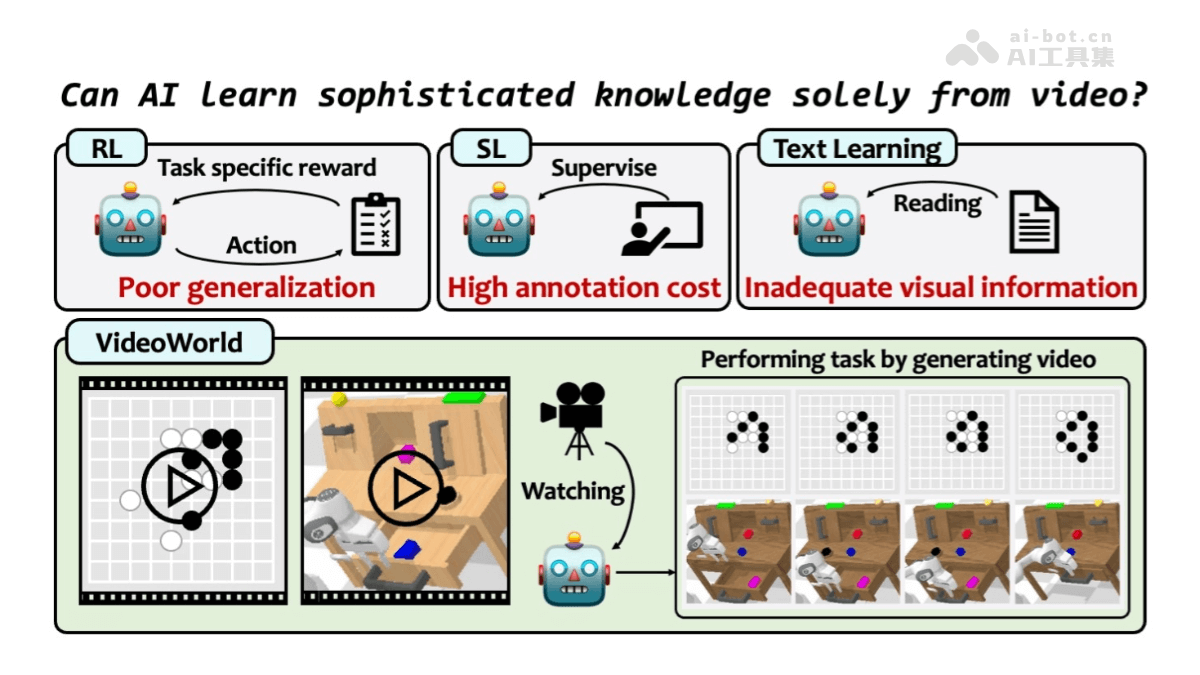
VideoWorld是北京交通大学、中国科学技术大学和字节跳动合作开展的一项研究项目,探索深度生成模型是否能仅通过未标注的视频数据学习复杂的知识,包括规则、推理和规划能力。该项目的核心是自回归视频生成模型,通过观察视频来获取知识,不依赖于传统的文本或标注数据。
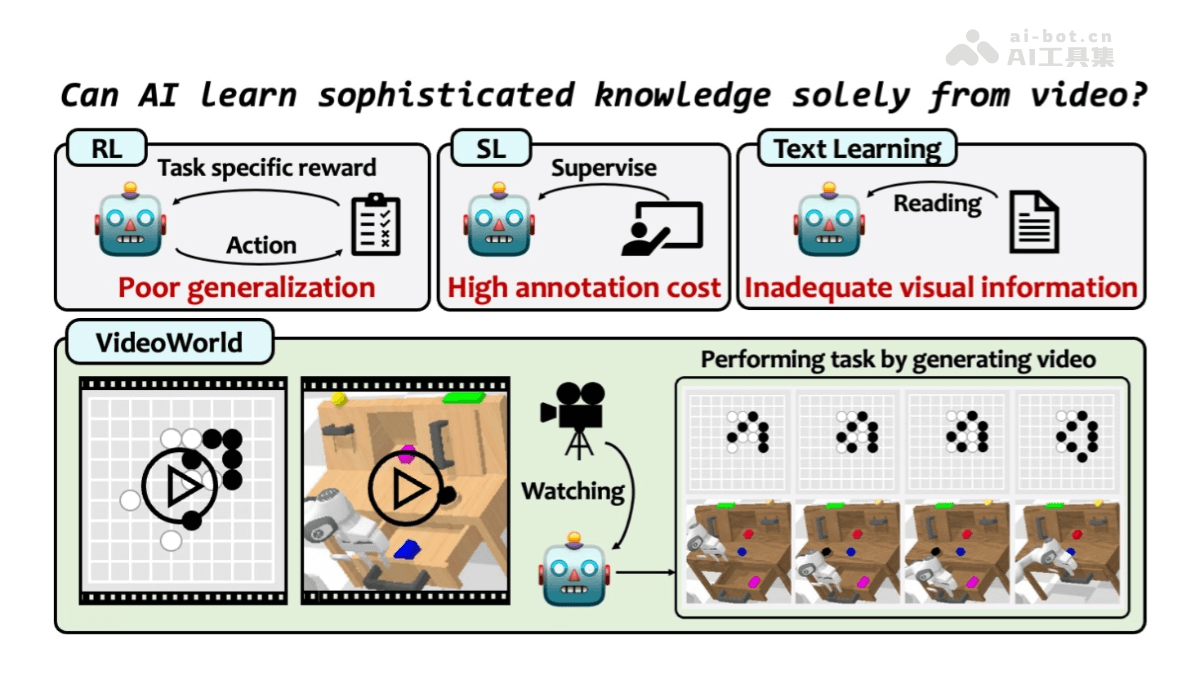
从未标注视频中学习复杂知识:VideoWorld 能仅通过未标注的视频数据学习复杂的任务知识,包括规则、推理和规划能力,无需依赖语言指令或标注数据。自回归视频生成:使用 VQ-VAE 和自回归 Transformer 架构,VideoWorld 可以生成高质量的视频帧,通过生成的视频帧推断出任务相关的操作。长期推理和规划:在围棋任务中,VideoWorld 能进行长期规划,选择最佳落子位置并击败高水平的对手(如 KataGo-5d)。 在机器人任务中,VideoWorld 能够规划复杂的操作序列,完成多种机器人控制任务。跨环境泛化能力:VideoWorld 能在不同的任务和环境中迁移所学的知识,表现出良好的泛化能力。 紧凑的视觉信息表示:LDM 将冗长的视觉信息压缩为紧凑的潜在代码,减少了信息冗余,提高了学习效率。 这种紧凑表示使模型能够更高效地处理复杂的视觉动态,支持长期推理和决策。无需强化学习的自主学习:VideoWorld 不依赖于传统的强化学习方法(如搜索算法或奖励机制),而是通过纯视觉输入自主学习复杂的任务。高效的知识学习与推理:VideoWorld 在围棋任务中达到了 5 段专业水平(Elo 2317),仅使用 3 亿参数,展示了其高效的知识学习能力。 在机器人任务中,VideoWorld 的任务成功率接近 oracle 模型,表现出高效推理和决策的能力。视觉信息的深度理解:VideoWorld 能通过生成的视频帧和潜在代码,理解复杂的视觉信息,支持任务驱动的推理和决策。支持多种任务类型:VideoWorld 不仅适用于围棋和机器人控制任务,还具有扩展到其他复杂任务的潜力,如自动驾驶、智能监控等领域。
VQ-VAE(矢量量化-变分自编码器):用于将视频帧编码为离散的 token 序列。VQ-VAE 通过矢量量化将连续的图像特征映射到离散的码本(codebook)中,生成离散的表示。自回归 Transformer:基于离散 token 序列进行下一个 token 的预测。Transformer 架构利用自回归机制,根据前面的帧预测下一帧,从而生成连贯的视频序列。潜在动态模型(LDM):引入 LDM,将多步视觉变化压缩为紧凑的潜在代码,提高知识学习的效率和效果。LDM 能捕捉视频中的短期和长期动态,支持复杂的推理和规划任务。视频生成与任务操作的映射: 在生成视频帧的基础上,VideoWorld 进一步通过逆动态模型(Inverse Dynamics Model, IDM)将生成的视频帧映射为具体的任务操作。 IDM 是一个独立训练的模块,通常由多层感知机(MLP)组成,能根据当前帧和生成的下一帧预测出相应的动作。数据驱动的知识学习:VideoWorld 通过大规模的未标注视频数据进行学习,减少了对人工标注数据的依赖,降低了数据准备的成本。
项目官网:https://maverickren.github.io/VideoWorldGitHub仓库:https://github.com/bytedance/VideoWorldarXiv技术论文:https://arxiv.org/pdf/2501.09781
自动驾驶:通过车载摄像头的视频输入,VideoWorld 可以学习道路环境的动态变化,识别交通标志、行人和障碍物。智能监控:通过观察监控视频,VideoWorld 可以学习正常和异常行为的模式,实时检测异常事件。故障检测:通过观察生产过程的视频,VideoWorld 可以学习正常和异常状态的模式,实时检测故障。游戏 AI:需要模型能根据游戏环境生成合理的操作,与玩家或其他 AI 对抗。通过观察游戏视频,VideoWorld 可以学习游戏规则和环境动态。故障检测:通过观察生产过程的视频,VideoWorld 可以学习正常和异常状态的模式,实时检测故障。

提供免费的音视频转文字和翻译服务

“语言学习、会议记录、生成字幕”
张三录制了一段英语课堂音频,上传到该网站生成文字稿
李四下载了一部TED演讲视频,使用该网站提取英文字幕翻译成中文
王五在网站上上传法语歌曲音频,利用该网站翻译成中文歌词
语音转文字
视频字幕提取
多语言翻译
https://www.freesubtitles.ai/
小编发现FreeSubtitles.Ai网站非常受用户欢迎,请访问FreeSubtitles.Ai网址入口试用。

一键生成创作文案

“适用于需要创作各类文案的用户,包括新媒体运营人员、职场人士、创意写手等。”
根据提供的主题或内容,生成各类文案
提供多种创作模板和功能
适用于新媒体运营、职场效率提升、创意功能写作等场景
https://ai.jijianzn.com/web/
小编发现极简智能王网站非常受用户欢迎,请访问极简智能王网址入口试用。

快速阅读、提取、总信息

“适用于需要快速阅读、提取和汇总文档信息的用户,尤其适合研究人员、学生和专业人士。”
快速提取文档信息
定位关键信息
生成中文摘要
上传文档进行问答
https://read.youdao.com/
小编发现有道速读网站非常受用户欢迎,请访问有道速读网址入口试用。

一键音频清理,自动去除背景噪音,提升语音质量

“适用于播客、YouTube视频等场景”
播客
YouTube
音频
一键音频清理
自动去除背景噪音
回声降低
自动音量调整
https://audo.ai/
小编发现Audo Studio网站非常受用户欢迎,请访问Audo Studio网址入口试用。

使用Visme创建引人入胜的内容

“Visme适用于各种场景,包括市场营销、销售、人力资源、培训和发展、非营利组织、教育和企业等。”
多种类型的模板和设计元素
AI图像生成器
适用于各种场景
个人、商业和教育三个版本
小编发现Visme网站非常受用户欢迎,请访问Visme网址入口试用。

照片、视频编辑和设计工具

用于照片和视频编辑和设计
照片编辑
视频编辑
美颜相机
滤镜
去除背景
贴纸
文字
音乐
AR特效
模板
美容相机
照片转卡通
拼贴
模糊
马赛克
内容创作
https://www.beautyplus.com
小编发现BeautyPlus网站非常受用户欢迎,请访问BeautyPlus网址入口试用。

Step-1o Vision 是阶跃星辰最新研发的原生端到端多模态生成与理解一体化模型中的视觉版本。专注于视觉任务,具备强大的图像识别、感知、推理和指令跟随能力,能处理复杂的视觉输入并生成准确的文本描述或进行逻辑推理。在多个权威榜单中表现优异,适用于多种视觉任务,能为用户提供高效、智能的视觉理解解决方案。

复杂场景识别:能精准识别各种复杂图像,包括自然场景、物体细节、图表等,即使在图像质量欠佳或存在遮挡、变形的情况下也能准确识别关键要素。多语言理解:支持多语言文字的识别与翻译,能处理图像中的不同语言内容,例如识别并翻译小字的意大利语。细节捕捉:能捕捉图像中的微小但重要的视觉细节,例如识别图中的圆形等关键信息,并进行正确解读。逻辑推理:能根据图像内容进行复杂推理,例如识别真假折叠屏手机的设计优缺点,分析其实际应用中的可行性。空间关系理解:能够理解图像中的物理空间关系,例如解决“把某件物品拿出来,需要几步”的推理类题目,准确识别多层堆叠物品的空间关系并给出正确的操作步骤。图表分析:能通过表格、logo 等元素精准识别软件工具,结合常识对软件特点进行总结说明。指令跟随与交互能力:能理解用户输入的指令,结合图像内容生成准确的回应。模型具备一定的幽默感和互动性,能以更自然的方式与用户进行交互。深度视觉理解:Step-1o Vision 能进行更深入的视觉信息提取和推理。能注意到图像中被遗漏的细节(如红圈超出黑线的部分),准确解读其含义。模型能结合常识对图像中的内容进行推理和总结,例如分析博士工作的特性、软件工具的优缺点等。
端到端多模态架构端到端设计:Step-1o Vision 是端到端的多模态生成与理解一体化模型。从输入(图像、文本)到输出(文本描述、推理结果)的整个过程是无缝衔接的,无需依赖外部模块或预处理步骤。