

FilmAgent是什么
FilmAgent是哈尔滨工业大学(深圳)的研究团队开发的基于多智能体协作框架的虚拟电影制作工具,通过自动化流程实现虚拟3D空间中的端到端电影制作。模拟传统电影工作室的工作流程,用多智能体协作来自动化虚拟电影的制作。模拟了电影制作中的关键角色,包括导演、编剧、演员和摄影师,将整个制作过程分为三个阶段:规划、剧本创作和摄影。
FilmAgent是哈尔滨工业大学(深圳)的研究团队开发的基于多智能体协作框架的虚拟电影制作工具,通过自动化流程实现虚拟3D空间中的端到端电影制作。模拟传统电影工作室的工作流程,用多智能体协作来自动化虚拟电影的制作。模拟了电影制作中的关键角色,包括导演、编剧、演员和摄影师,将整个制作过程分为三个阶段:规划、剧本创作和摄影。

人工智能聊天机器人

[“提升企业客户服务体验”,”获取用户需求和行为数据”,”节省人工客服成本”,”为企业网站、APP等接入智能聊天机器人”]
在企业官网加入ServiBot,提供7*24小时智能客服
将ServiBot接入手机APP,提升用户粘性
企业内部使用ServiBot收集用户反馈意见
易于集成,一分钟即可接入项目中
可高度自定义外观、对话等
智能对话理解用户需求
提供用户行为分析
https://www.servibot.io/
小编发现ServiBot网站非常受用户欢迎,请访问ServiBot网址入口试用。

Whisper Input 是开源的语音输入工具,基于 Python 和 OpenAI 的 Whisper 模型开发。通过简单的快捷键操作(如按下 Option 键开始录音,松开结束录音),实现语音的实时转录和翻译。项目支持多语言语音输入,可将中文翻译为英文,适合多种语言环境的用户。

实时语音转录:通过简单的快捷键操作(如按下 Option 键开始录音,松开结束录音),将语音实时转换为文本。多语言支持:支持多种语言的语音输入和转录,包括但不限于中文、英文、日文等,支持中英文混合语音的识别。翻译功能:可以将中文语音翻译为英文,满足跨语言输入的需求。高效转录:使用 Groq 的 Whisper Large V3 Turbo 模型或 SiliconFlow 的 FunAudioLLM/SenseVoiceSmall 模型,转录速度快,大约在1-2 秒内完成。标点符号自动生成:转录时会自动生成标点符号,无需手动添加,提升文本的可读性。免费使用:通过 SiliconFlow 提供的免费 API Key,用户可以无限制地使用转录功能,无需付费或绑定信用卡。本地运行:支持在本地环境运行,用户只需安装 Python 和相关依赖即可使用,确保数据隐私和安全性。
Whisper 模型:Whisper 是 OpenAI 开发的深度学习模型,采用编码器-解码器 Transformer 架构,专门用于语音识别任务。支持多语言识别和翻译,并在大规模数据上进行训练,能将音频信号转换为文本。音频采集与处理:Whisper Input 使用 Python 的 pyaudio 库来实时采集麦克风输入的音频数据。音频数据通过缓冲区存储,并以指定的采样率(如 16kHz)进行处理。
GitHub仓库:https://github.com/ErlichLiu/Whisper-Input
会议记录:Whisper Input 可以实时将会议中的发言内容转录为文本,帮助记录人员快速整理会议纪要,确保信息的准确性和完整性。在多语言会议中,能提供实时翻译功能,帮助跨国团队克服语言障碍。教育领域:在在线教育和课堂讲解中,Whisper Input 能将教师的讲解内容实时转换为文本,供学生复习和巩固知识。还能为教育视频自动生成字幕,提升学习体验。智能语音交互:Whisper Input 可集成到智能家居和车载系统中,通过语音指令控制设备操作,如播放音乐、调节温度等,提升用户体验和安全性。还可用于智能客服系统,快速识别客户语音请求并提供即时回复。内容创作与媒体制作:对于视频创作者和媒体平台,Whisper Input 可自动生成多语言字幕,支持不同语言的用户群体,提升内容的可访问性和传播范围。

AI聊天工具,尽在Setapp

用于日常工作、写作、编码等任务
使用AI聊天生成创意文章
利用AI聊天辅助代码编写
通过AI聊天进行多语言翻译
生成、翻译、编辑文本
代码工作
AI助手
https://setapp.sjv.io/c/3944608/1857409/5114
小编发现TypingMind on Setapp网站非常受用户欢迎,请访问TypingMind on Setapp网址入口试用。
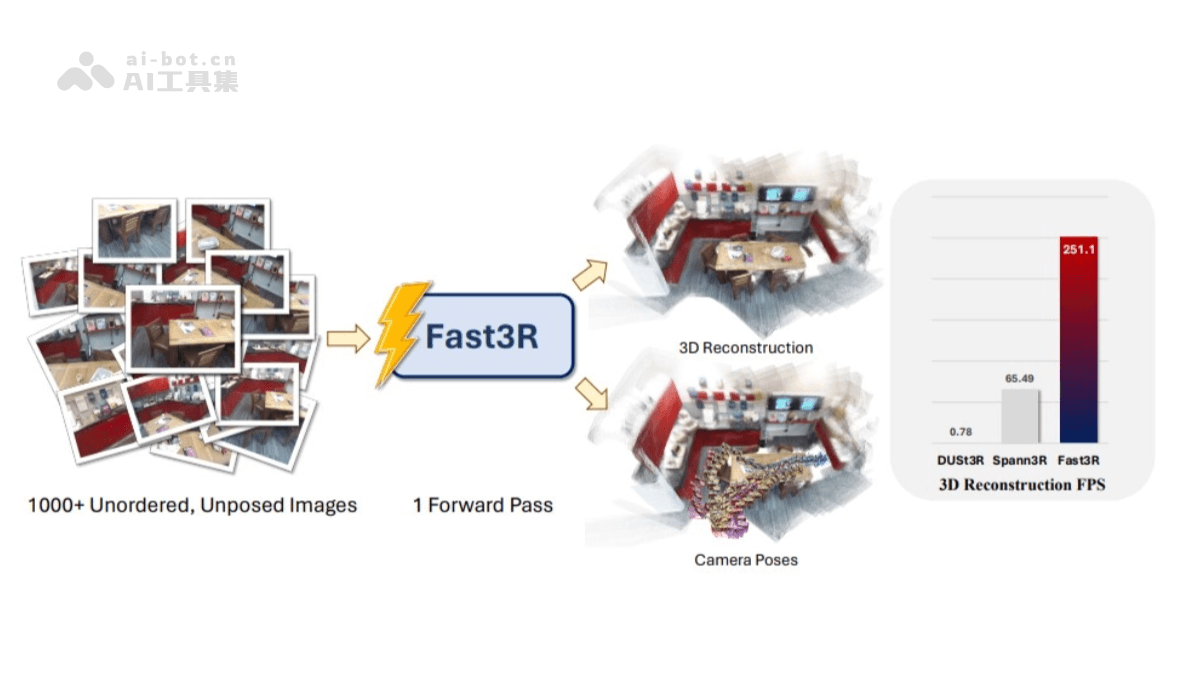
Fast3R是Meta和密歇根大学的研究人员提出的新型的多视图3D重建方法,基于Transformer架构,能在一个前向传播过程中处理1000多张图像,实现高效且可扩展的3D重建。与传统方法相比,Fast3R摒弃了逐对处理图像和全局对齐的复杂步骤,通过并行处理多个视图,提高了推理速度,减少误差累积。核心优势在于并行处理能力和对多视图的支持。能同时处理多个图像,每个图像都可以同时关注其他所有图像,在重建过程中减少误差累积。
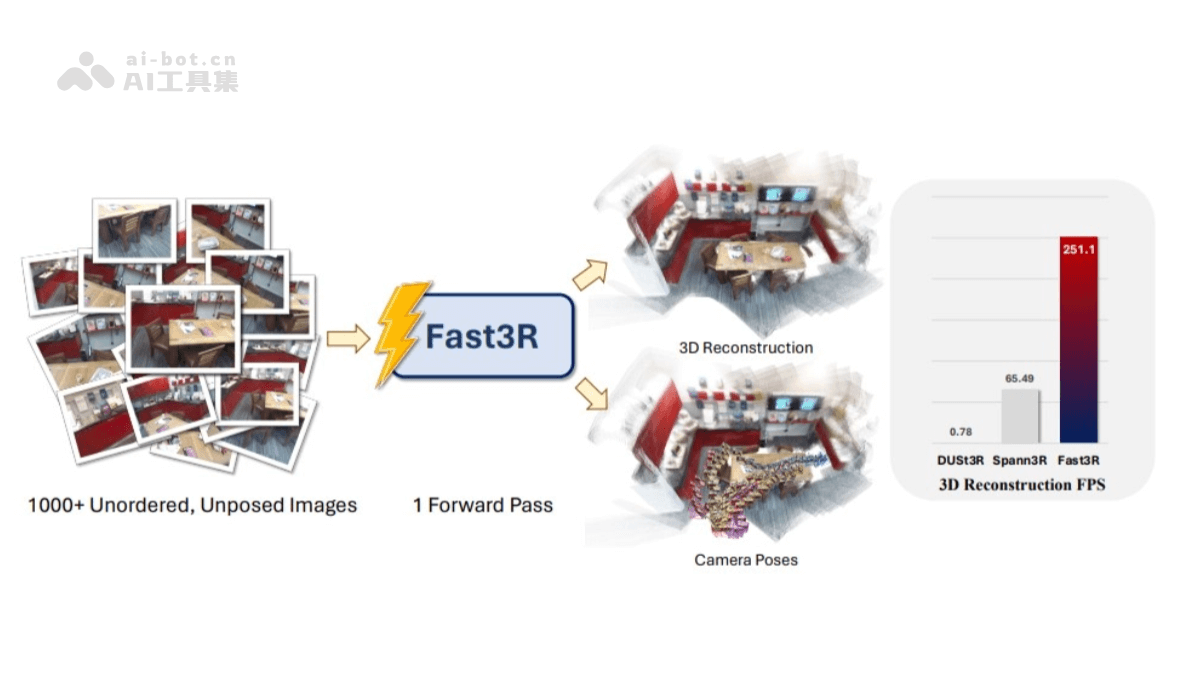
高效多视图处理:Fast3R能在单次前向传递中处理1000多张图像,并行处理多个视图,提高了3D重建的效率。避免了传统成对处理图像和全局对齐的复杂步骤,减少了误差累积。高精度重建:Fast3R基于Transformer架构,能精确地估计相机姿态并重建3D场景。在相机姿态估计和3D重建的实验中展现出最先进的性能,在处理复杂场景时表现出色。可扩展性强:Fast3R在训练时可以使用较少的视图,在推理时扩展到更多的视图,在处理大规模数据集时具有更高的灵活性。快速推理:与传统方法相比,Fast3R显著提高了推理速度。如,MV-DUSt3R(Fast3R的前身)在处理4至24个输入视图时,比DUSt3R快48倍至78倍。
并行处理与单次前向传递:Fast3R能在一次前向传递中处理超过1000张图像。通过Transformer架构并行处理多个视图,避免了传统方法中逐对处理图像和全局对齐的复杂步骤。Transformer架构:Fast3R采用Transformer架构,支持每个图像同时关注其他所有图像。全连接的自注意力机制使得模型能更好地理解不同视图之间的关系,提高重建精度。位置嵌入与图像索引嵌入:为了处理多个视图,Fast3R引入了图像索引位置嵌入。帮助模型识别哪些图像块来自同一张图像,定义全局坐标系。使模型能在训练时使用较少的视图,在推理时扩展到更多的视图。点图预测与解码器:Fast3R使用独立的解码器头将Transformer的输出映射到局部和全局点图。提供了3D场景的详细表示,同时模型还生成置信度图以评估重建的可靠性。
项目官网:https://fast3r-3d.github.io/arXiv技术论文:https://arxiv.org/pdf/2501.13928
机器人视觉:Fast3R能快速处理大量图像并重建3D场景,机器人可以通过多视角的图像输入,快速重建周围环境的3D模型,更好地规划路径、识别障碍物并执行任务。增强现实(AR):在增强现实应用中,Fast3R可以实时处理多个视角的图像,快速生成高精度的3D场景模型。虚拟现实(VR):Fast3R能高效地从多视角图像中重建出高精度的3D场景,通过快速处理大量图像,Fast3R可以生成逼真的3D环境,让用户在虚拟世界中获得更真实的视觉体验。文化遗产保护:Fast3R可以用于文化遗产的数字化重建。通过多视角拍摄文物或古迹,Fast3R能快速生成高精度的3D模型,便于文物的保护、研究和展示。自动驾驶:在自动驾驶领域,Fast3R可以处理车辆摄像头捕获的多视角图像,快速重建周围环境的3D模型。

快速创建交互式AI,支持自定义问答

“适用于需要快速建立自助客服的企业,包括电商、SaaS软件、网络服务等。”
小明使用FrequentlyAskedAI在一个月内制作了一个包含500个问题的智能问答机器人,嵌入到他的在线商店,每天可以回答超过2000个顾客提问,大大降低了人工客服负担。
小红是一名程序员,使用FrequentlyAskedAI轻松创建了一个代码常见问题解答机器人,内置了300个开发相关问题,放在他的博客上,能够过滤掉很多重复提问,提高工作效率。
小蓝的SaaS软件使用FrequentlyAskedAI快速生成了客户常见问题自助提问机器人,集成到产品内,大大减少了每天需要人工回复的问题数量,客户满意度提高了20%。
自定义问答
情感交互
多语言支持
https://www.frequentlyaskedai.com/
小编发现FrequentlyAskedAI网站非常受用户欢迎,请访问FrequentlyAskedAI网址入口试用。

Tarsier2是字节跳动推出的先进的大规模视觉语言模型(LVLM),生成详细且准确的视频描述,在多种视频理解任务中表现出色。模型通过三个关键升级实现性能提升,将预训练数据从1100万扩展到4000万视频文本对,丰富了数据量和多样性;在监督微调阶段执行精细的时间对齐;基于模型采样自动构建偏好数据,应用直接偏好优化(DPO)训练。 在DREAM-1K基准测试中,Tarsier2-7B的F1分数比GPT-4o高出2.8%,比Gemini-1.5-Pro高出5.8%。在15个公共基准测试中取得了新的最佳结果,涵盖视频问答、视频定位、幻觉测试和具身问答等任务。

详细视频描述:Tarsier2能生成高质量的视频描述,覆盖视频中的各种细节,包括动作、场景和情节。视频问答:能回答关于视频的具体问题,展现出强大的时空理解和推理能力。视频定位:Tarsier2可以检测并定位视频中特定事件的发生时间,支持多视频段的定位。幻觉测试:通过优化训练策略,Tarsier2显著减少了模型生成虚假信息的可能性。多语言支持:支持多种语言的视频描述生成,进一步拓展了其应用场景。
大规模预训练数据:Tarsier2将预训练数据从1100万扩展到4000万视频-文本对,提升了数据的规模和多样性。数据包括来自互联网的短视频、电影或电视剧的解说视频,通过多模态LLM自动生成的视频描述和问答对。细粒度时间对齐的监督微调(SFT):在监督微调阶段,Tarsier2引入了15万条细粒度标注的视频描述数据,每条描述都对应具体的时间戳。时间对齐的训练方式显著提高了模型在视频描述任务中的准确性和细节捕捉能力,同时减少了生成幻觉。直接偏好优化(DPO):Tarsier2通过模型采样自动构建偏好数据,应用直接偏好优化(DPO)进行训练。基于模型生成的正负样本对,进一步优化模型的生成质量,确保生成的视频描述更符合人类的偏好。
GitHub仓库:https://github.com/bytedance/tarsierarXiv技术论文:https://arxiv.org/pdf/2501.07888
视频描述:Tarsier2 能生成高质量的详细视频描述,涵盖视频中的各种细节,包括动作、场景和情节。幻觉测试:Tarsier2 在减少生成幻觉方面表现出色。通过直接偏好优化(DPO)和细粒度时间对齐的训练,Tarsier2 显著降低了生成虚假信息的可能性。多语言支持:Tarsier2 支持多语言的视频描述生成,能满足不同语言环境下的需求。具身问答:Tarsier2 在具身问答(Embodied QA)任务中也表现出色,能结合视觉和语言信息,为具身智能体提供准确的指导。

Blerp是一个AI TTS声音模因、表情GIF和声音提示的产品。

用于聊天和直播社区中播放声音模因、表情GIF和声音提示。
观众可以在Twitch上使用Blerp Sound Memes分享声音模因
主播可以在YouTube上使用Blerp Sound Memes播放声音提示
观众可以在Tiktok上使用Blerp Sound Memes收集频道积分
AI TTS声音模因
表情GIF
声音提示
多语言支持
聊天面板
频道积分
WalkOn Sounds
https://chrome.google.com/webstore/detail/blerp-sound-memes-ai-tts/cniifghobhghnieljgdanjopjnamgfle?hl=en
小编发现Blerp Sound Memes. AI TTS Voices Emotes GIFS网站非常受用户欢迎,请访问Blerp Sound Memes. AI TTS Voices Emotes GIFS网址入口试用。

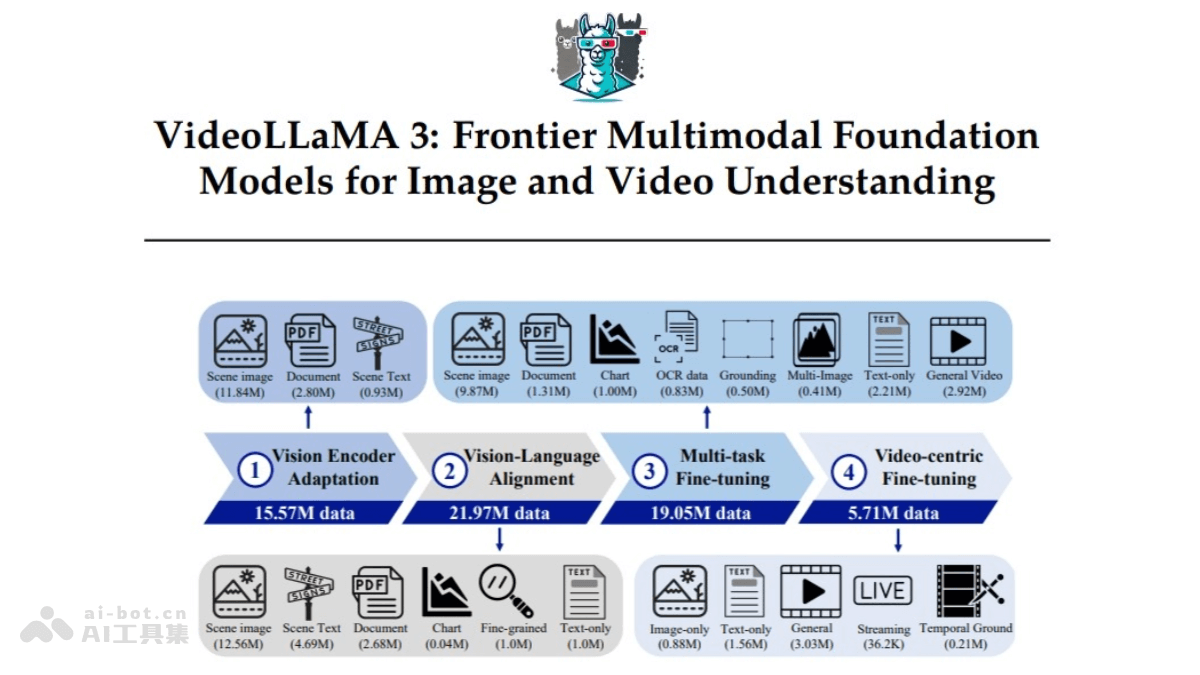
VideoLLaMA3 是阿里巴巴开源的前沿多模态基础模型,专注于图像和视频理解。基于 Qwen 2.5 架构,结合了先进的视觉编码器(如 SigLip)和强大的语言生成能力,能高效处理长视频序列,支持多语言的视频内容分析和视觉问答任务。模型具备强大的多模态融合能力,支持视频、图像输入,生成自然语言描述,适用于视频内容分析、视觉问答和多模态应用等多种场景。 VideoLLaMA3 提供多种预训练版本(如 2B 和 7B 参数规模),针对大规模数据进行了优化,具备高效的时空建模能力和跨语言理解能力。
多模态输入与语言生成:支持视频和图像的多模态输入,能生成自然语言描述,帮助用户快速理解视觉内容。视频内容分析:用户可以上传视频,模型会提供详细的自然语言描述,适用于快速提取视频核心信息。视觉问答:结合视频或图像输入问题,模型能生成准确的答案,适用于复杂的视觉问答任务。多语言支持:具备跨语言视频理解能力,支持多语言生成。高效的时空建模:优化的时空建模能力使其能够处理长视频序列,适用于复杂的视频理解任务。多模态融合:结合视频和文本数据进行内容生成或分类任务,提升模型在多模态应用中的性能。灵活的部署方式:支持本地部署和云端推理,适应不同的使用场景。
视觉为中心的训练范式:VideoLLaMA3 的核心在于高质量的图像文本数据,非大规模的视频文本数据。其训练分为四个阶段:视觉对齐阶段:热身视觉编码器和投影仪,为后续训练做准备。视觉语言预训练阶段:使用大规模图像文本数据(如场景图像、文档、图表)和纯文本数据,联合调整视觉编码器、投影仪和语言模型。多任务微调阶段:结合图像文本数据进行下游任务优化,并引入视频文本数据以建立视频理解基础。视频为中心的微调阶段:进一步提升模型在视频理解任务中的表现。视觉为中心的框架设计:视觉编码器被优化为能根据图像尺寸生成相应数量的视觉标记,不是固定数量的标记,更好地捕捉图像中的细粒度细节。对于视频输入,模型通过减少视觉标记的数量来提高表示的精确性和紧凑性。基于 Qwen 2.5 架构的多模态融合:VideoLLaMA3 基于 Qwen 2.5 架构,结合了先进的视觉编码器(如 SigLip)和强大的语言生成能力,能高效处理复杂的视觉和语言任务。
GitHub仓库:https://github.com/DAMO-NLP-SG/VideoLLaMA3HuggingFace模型库:https://huggingface.co/papers/2501.13106arXiv技术论文:https://arxiv.org/pdf/2501.13106
视频内容分析:VideoLLaMA3 能深度理解和分析长视频内容,捕捉视频中的细微动作和长期记忆。可以自动检测视频中的异常行为或生成视频的详细描述,帮助用户快速了解视频核心内容。视频问答系统:在视频问答(VideoQA)任务中,用户可以针对视频内容提出问题,VideoLLaMA3 能生成准确的答案。视频字幕生成:基于其流式字幕生成能力,VideoLLaMA3 可以为视频自动生成实时字幕。多语言支持:VideoLLaMA3 支持多语言生成,能处理跨语言的视频理解任务。在国际化的视频内容分析和多语言教育场景中具有广泛的应用潜力。

与DeepSeek AI聊天

“DeepSeek 可广泛应用于在线客服、智能助手、聊天机器人等场景。”
公司网站的在线客服功能
智能助手帮助用户解答问题
社交平台上的聊天机器人
回答问题
提供建议
进行闲聊
https://chat.deepseek.com/sign_in
小编发现DeepSeek网站非常受用户欢迎,请访问DeepSeek网址入口试用。