
VideoChat-Flash是什么
VideoChat-Flash 是上海人工智能实验室和南京大学等机构联合开发的针对长视频建模的多模态大语言模型(MLLM),模型通过分层压缩技术(HiCo)高效处理长视频,显著减少计算量,同时保留关键信息。采用多阶段从短到长的学习方案,结合真实世界长视频数据集 LongVid,进一步提升对长视频的理解能力。
VideoChat-Flash的主要功能
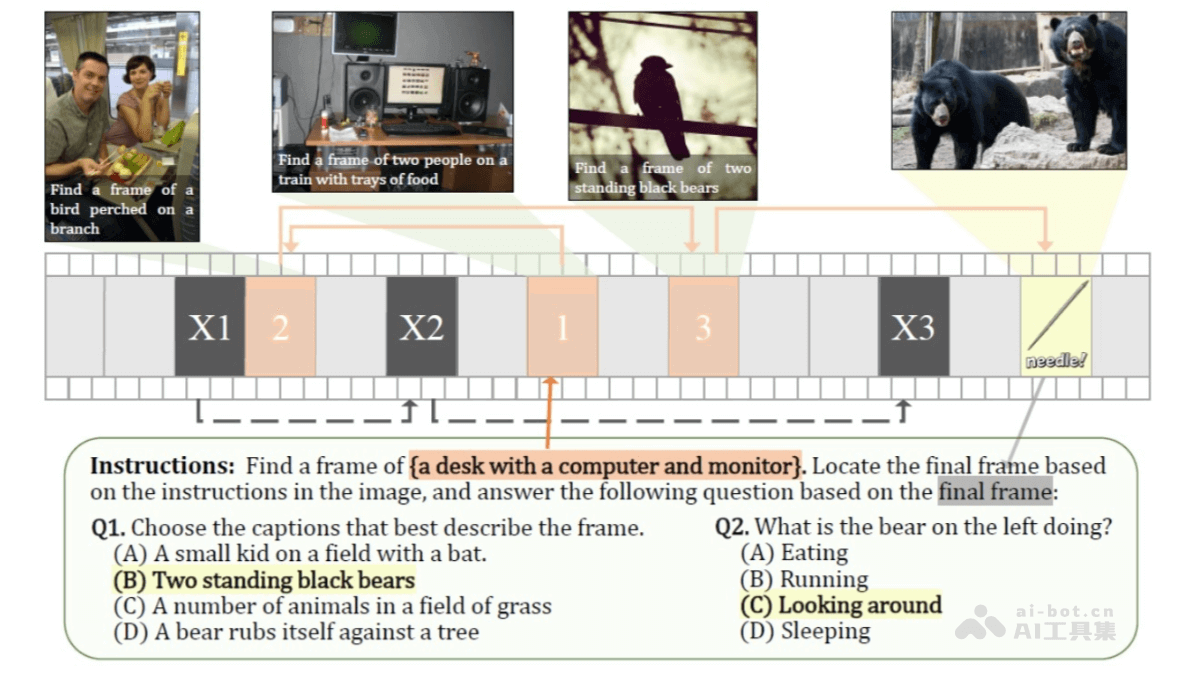
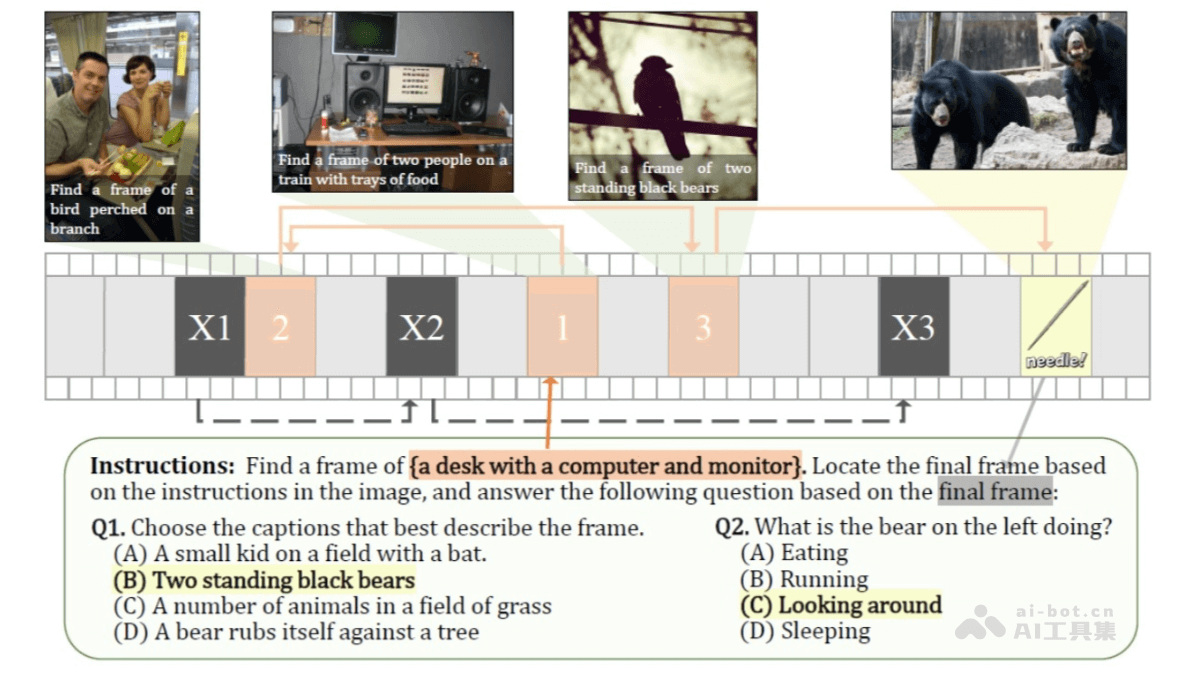
长视频理解能力:VideoChat-Flash 通过分层压缩技术(HiCo)有效处理长视频,能处理长达数小时的视频内容。在“针在干草堆中”(NIAH)任务中,首次在开源模型中实现了 10,000 帧(约 3 小时视频)的 99.1% 准确率。高效模型架构:模型通过将每个视频帧编码为仅 16 个 token,显著降低了计算量,推理速度比前代模型快 5-10 倍。多阶段从短到长的学习方案,结合真实世界的长视频数据集 LongVid,进一步提升了模型的性能。强大的视频理解能力:VideoChat-Flash 在多个长视频和短视频基准测试中均表现出色,超越了其他开源 MLLM 模型,甚至在某些任务中超过了规模更大的模型。多跳上下文理解:VideoChat-Flash 支持多跳 NIAH 任务,能追踪长视频中的多个关联图像序列,进一步提升了对复杂上下文的理解能力。
VideoChat-Flash的技术原理
分层压缩技术(HiCo):HiCo 是 VideoChat-Flash 的核心创新之一,旨在高效处理长视频中的冗余视觉信息。片段级压缩:将长视频分割为较短的片段,对每个片段进行独立编码。视频级压缩:在片段编码的基础上,进一步压缩整个视频的上下文信息,减少需要处理的标记数量。语义关联优化:结合用户查询的语义信息,进一步减少不必要的视频标记,从而降低计算量。多阶段学习方案:VideoChat-Flash 采用从短视频到长视频的多阶段学习方案,逐步提升模型对长上下文的理解能力。初始阶段:使用短视频及其注释进行监督微调,建立模型的基础理解能力。扩展阶段:逐步引入长视频数据,训练模型处理更复杂的上下文。混合语料训练:最终在包含短视频和长视频的混合语料上进行训练,以实现对不同长度视频的全面理解。真实世界长视频数据集 LongVid:为了支持模型训练,研究团队构建了 LongVid 数据集,包含 30 万小时的真实世界长视频和 2 亿字的注释。该数据集为模型提供了丰富的训练素材,使其能够更好地适应长视频理解任务。模型架构:VideoChat-Flash 的架构包括三个主要部分:视觉编码器、视觉-语言连接器和大语言模型(LLM)。通过这种分层架构,模型能高效地将视频内容编码为紧凑的标记序列,通过 LLM 进行长上下文建模。
VideoChat-Flash的项目地址
GitHub仓库:https://github.com/OpenGVLab/VideoChat-FlasharXiv技术论文:https://arxiv.org/pdf/2501.00574
VideoChat-Flash的应用场景
视频字幕生成与翻译:模型能生成详细且准确的视频字幕,适用于多语言翻译和无障碍字幕生成,帮助观众更好地理解视频内容。视频问答与交互:VideoChat-Flash 支持基于视频内容的自然语言问答,用户可以通过提问获取视频中的关键信息,例如电影剧情解析、纪录片中的知识点等。具身AI与机器人学习:在具身AI领域,VideoChat-Flash 可以通过长时间的自我视角视频帮助机器人学习复杂的任务,例如制作咖啡等,通过分析视频中的关键事件来指导机器人完成任务。体育视频分析与集锦生成:模型能分析体育比赛视频,提取关键事件并生成集锦,帮助观众快速了解比赛的精彩瞬间。监控视频分析:VideoChat-Flash 可以处理长时间的监控视频,识别和追踪关键事件,提高监控系统的效率和准确性。