

Signapse官网
用AI构建自动手语翻译

Signapse简介
需求人群:
适用于与聋哑人士进行交流的场景,如学校、医院、社交活动等。
产品特色:
实时翻译手语为文字
语音合成
与聋哑人士的交互
Signapse官网入口网址
https://www.signapse.ai/
小编发现Signapse网站非常受用户欢迎,请访问Signapse网址入口试用。
用AI构建自动手语翻译
适用于与聋哑人士进行交流的场景,如学校、医院、社交活动等。
实时翻译手语为文字
语音合成
与聋哑人士的交互
https://www.signapse.ai/
小编发现Signapse网站非常受用户欢迎,请访问Signapse网址入口试用。

与任何PDF文档聊天

“PdfPal AI适用于需要处理PDF文档的个人和企业用户,可以用于学术研究、商业分析、法律文件等领域。”
上传PDF文档
AI驱动的聊天功能
智能文档分析
即时答案和摘要
安全上传
https://pdfpal.ai/
小编发现PdfPal AI网站非常受用户欢迎,请访问PdfPal AI网址入口试用。

核韬AI是一款集艺术与科技于一体的人工智能产品,能够将任何事物转化为AI生成的内容,为用户提供全新的创作和体验方式。
网站服务:AI图片优化修复,AI绘画生成器,AI设计工具,图像生成,AI,AI,人工智能,内容生成,艺术创作,解决方案,设计辅助,图像AI,AI图片优化修复,AI绘画生成器,AI设计工具,图像生成,AI,AI,人工智能,内容生成,艺术创作,解决方案,设计辅助。

核韬AI官网-万物皆可AIGCwww.graffitiland.cn是深圳艾艺时代科技有限公司旗下网站,网站成立于2022年10月18日。网站主要内容为:核韬ai等。网站已经通过工信部备案,备案号为: 粤icp备2023070287号。
核韬AI是一款集艺术与科技于一体的人工智能产品,通过先进的算法和深度学习技术,能够将任何事物转化为AI生成的内容,为用户提供全新的创作和体验方式。
1. 图像转换:核韬AI可以将用户提供的图像转化为艺术作品,让普通照片变得更加艺术化。2. 文字生成:核韬AI可以根据用户输入的文字生成有趣、创意的句子或段落,帮助用户快速产生灵感。3. 音乐创作:核韬AI可以根据用户提供的音乐片段,自动生成完整的音乐作品,让用户轻松创作属于自己的音乐作品。4. 视频编辑:核韬AI可以将用户提供的视频素材进行智能编辑,自动生成精美的视频作品,让用户的创作更加出彩。
1. 高度智能化:核韬AI采用了先进的深度学习算法,能够自动学习和适应用户的需求,提供个性化的创作体验。2. 艺术化效果:核韬AI的算法能够将普通的图像、文字、音乐和视频转化为艺术作品,让用户的创作更加有创意和艺术感。3. 简单易用:核韬AI提供简洁直观的用户界面,操作简单方便,即使没有专业的技术背景,用户也能轻松上手。
1. 创意设计:核韬AI可以帮助设计师快速生成创意图案和艺术作品,提供灵感和创作素材。2. 广告营销:核韬AI可以根据用户提供的产品信息和广告需求,自动生成吸引人的广告素材,提升广告效果。3. 教育培训:核韬AI可以帮助教师和学生快速生成教学素材和创作作品,提升教学效果和学习兴趣。
1. 图像转换:用户只需上传自己的照片,选择喜欢的艺术风格,核韬AI即可将照片转化为艺术作品。2. 文字生成:用户输入想要生成的文字,选择风格和语气,核韬AI会自动生成有趣、创意的句子或段落。3. 音乐创作:用户上传自己的音乐片段,选择音乐风格和节奏,核韬AI会自动生成完整的音乐作品。4. 视频编辑:用户上传视频素材,选择编辑风格和特效,核韬AI会自动智能编辑生成精美的视频作品。
通过核韬AI,你可以轻松实现创作梦想,将平凡的事物转化为艺术作品,为你的创作和体验带来全新的可能性。快来体验核韬AI,开启艺术与科技的无限可能!
https://www.graffitiland.cn
AI聚合大数据显示,爱画之城官网非常受用户欢迎,请访问爱画之城网址入口(https://www.graffitiland.cn)试用。

免费AI音频过滤器,清理口语音频

广播、播客、音频制作
自动清除背景噪音
调整音量平衡
提升音频质量
https://podcast.adobe.com/enhance
小编发现Adobe Enhance Speech网站非常受用户欢迎,请访问Adobe Enhance Speech网址入口试用。

Whisper Input 是开源的语音输入工具,基于 Python 和 OpenAI 的 Whisper 模型开发。通过简单的快捷键操作(如按下 Option 键开始录音,松开结束录音),实现语音的实时转录和翻译。项目支持多语言语音输入,可将中文翻译为英文,适合多种语言环境的用户。

实时语音转录:通过简单的快捷键操作(如按下 Option 键开始录音,松开结束录音),将语音实时转换为文本。多语言支持:支持多种语言的语音输入和转录,包括但不限于中文、英文、日文等,支持中英文混合语音的识别。翻译功能:可以将中文语音翻译为英文,满足跨语言输入的需求。高效转录:使用 Groq 的 Whisper Large V3 Turbo 模型或 SiliconFlow 的 FunAudioLLM/SenseVoiceSmall 模型,转录速度快,大约在1-2 秒内完成。标点符号自动生成:转录时会自动生成标点符号,无需手动添加,提升文本的可读性。免费使用:通过 SiliconFlow 提供的免费 API Key,用户可以无限制地使用转录功能,无需付费或绑定信用卡。本地运行:支持在本地环境运行,用户只需安装 Python 和相关依赖即可使用,确保数据隐私和安全性。
Whisper 模型:Whisper 是 OpenAI 开发的深度学习模型,采用编码器-解码器 Transformer 架构,专门用于语音识别任务。支持多语言识别和翻译,并在大规模数据上进行训练,能将音频信号转换为文本。音频采集与处理:Whisper Input 使用 Python 的 pyaudio 库来实时采集麦克风输入的音频数据。音频数据通过缓冲区存储,并以指定的采样率(如 16kHz)进行处理。
GitHub仓库:https://github.com/ErlichLiu/Whisper-Input
会议记录:Whisper Input 可以实时将会议中的发言内容转录为文本,帮助记录人员快速整理会议纪要,确保信息的准确性和完整性。在多语言会议中,能提供实时翻译功能,帮助跨国团队克服语言障碍。教育领域:在在线教育和课堂讲解中,Whisper Input 能将教师的讲解内容实时转换为文本,供学生复习和巩固知识。还能为教育视频自动生成字幕,提升学习体验。智能语音交互:Whisper Input 可集成到智能家居和车载系统中,通过语音指令控制设备操作,如播放音乐、调节温度等,提升用户体验和安全性。还可用于智能客服系统,快速识别客户语音请求并提供即时回复。内容创作与媒体制作:对于视频创作者和媒体平台,Whisper Input 可自动生成多语言字幕,支持不同语言的用户群体,提升内容的可访问性和传播范围。

统一的多模态生成模型

“通用人工智能”
根据提示描述并生成图像
理解视频中的内容
根据音频生成文本描述
图像 caption
执行自由形式指令
图像编辑
对象检测
语义分割
表面法线估计
基于图像的音频生成
https://unified-io-2.allenai.org/
小编发现Unified-IO 2网站非常受用户欢迎,请访问Unified-IO 2网址入口试用。

AI聊天工具,尽在Setapp

用于日常工作、写作、编码等任务
使用AI聊天生成创意文章
利用AI聊天辅助代码编写
通过AI聊天进行多语言翻译
生成、翻译、编辑文本
代码工作
AI助手
https://setapp.sjv.io/c/3944608/1857409/5114
小编发现TypingMind on Setapp网站非常受用户欢迎,请访问TypingMind on Setapp网址入口试用。

AI 口袋导师

“学生可以使用 Studdy 来获取解答和辅导,适用于各种学科和年级。”
数学、化学、物理、摘要等多个学科支持
多语言翻译
聊天功能与 AI 助手交流
免费提供逐步解决方案
适用于 4 年级到大学阶段的数学课程
支持多种类型的数学问题
https://apps.apple.com/us/app/studdy-ai-pocket-tutor/id6450114499
小编发现Studdy AI网站非常受用户欢迎,请访问Studdy AI网址入口试用。
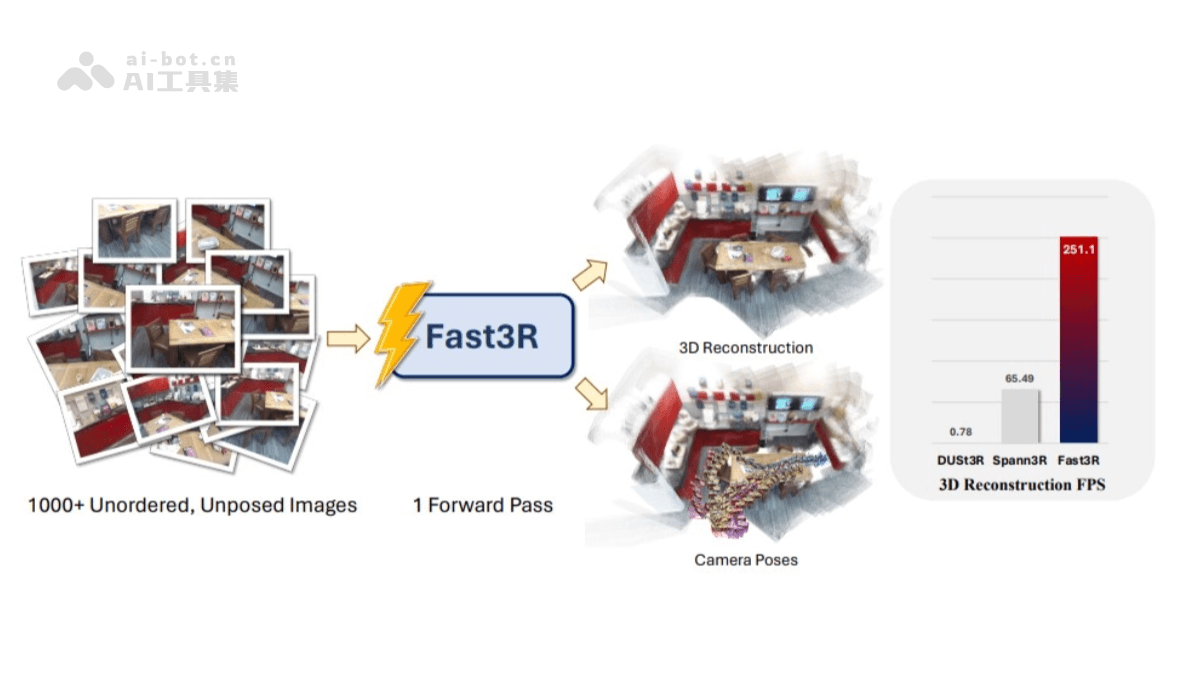
Fast3R是Meta和密歇根大学的研究人员提出的新型的多视图3D重建方法,基于Transformer架构,能在一个前向传播过程中处理1000多张图像,实现高效且可扩展的3D重建。与传统方法相比,Fast3R摒弃了逐对处理图像和全局对齐的复杂步骤,通过并行处理多个视图,提高了推理速度,减少误差累积。核心优势在于并行处理能力和对多视图的支持。能同时处理多个图像,每个图像都可以同时关注其他所有图像,在重建过程中减少误差累积。
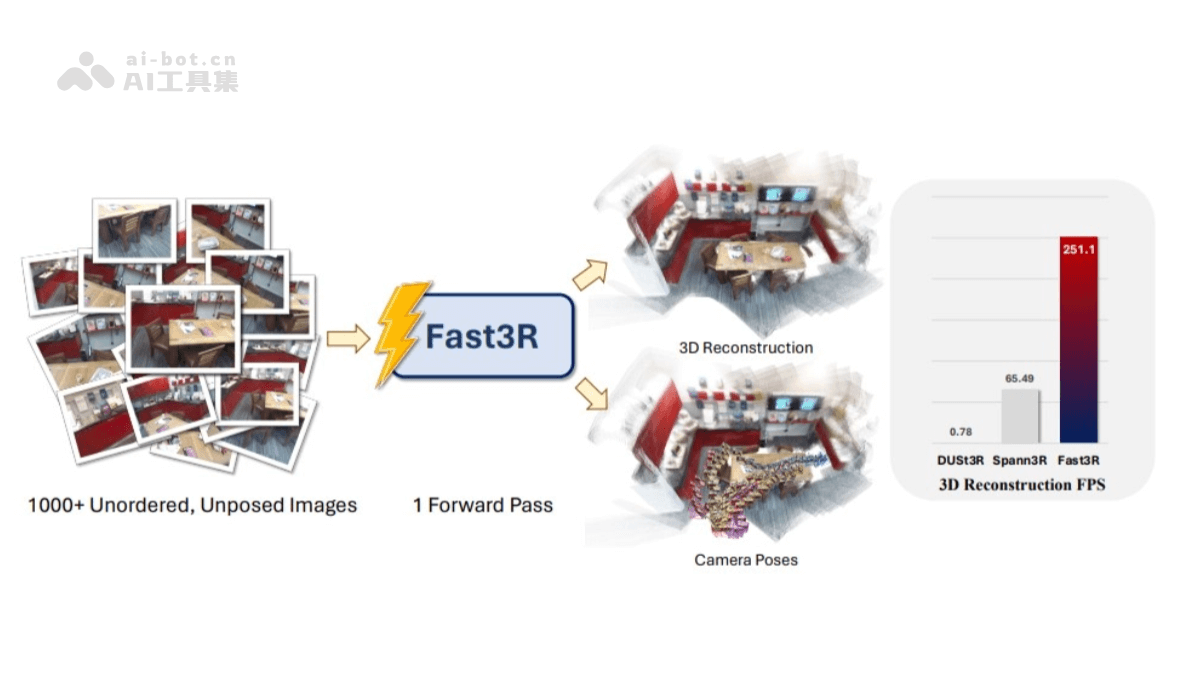
高效多视图处理:Fast3R能在单次前向传递中处理1000多张图像,并行处理多个视图,提高了3D重建的效率。避免了传统成对处理图像和全局对齐的复杂步骤,减少了误差累积。高精度重建:Fast3R基于Transformer架构,能精确地估计相机姿态并重建3D场景。在相机姿态估计和3D重建的实验中展现出最先进的性能,在处理复杂场景时表现出色。可扩展性强:Fast3R在训练时可以使用较少的视图,在推理时扩展到更多的视图,在处理大规模数据集时具有更高的灵活性。快速推理:与传统方法相比,Fast3R显著提高了推理速度。如,MV-DUSt3R(Fast3R的前身)在处理4至24个输入视图时,比DUSt3R快48倍至78倍。
并行处理与单次前向传递:Fast3R能在一次前向传递中处理超过1000张图像。通过Transformer架构并行处理多个视图,避免了传统方法中逐对处理图像和全局对齐的复杂步骤。Transformer架构:Fast3R采用Transformer架构,支持每个图像同时关注其他所有图像。全连接的自注意力机制使得模型能更好地理解不同视图之间的关系,提高重建精度。位置嵌入与图像索引嵌入:为了处理多个视图,Fast3R引入了图像索引位置嵌入。帮助模型识别哪些图像块来自同一张图像,定义全局坐标系。使模型能在训练时使用较少的视图,在推理时扩展到更多的视图。点图预测与解码器:Fast3R使用独立的解码器头将Transformer的输出映射到局部和全局点图。提供了3D场景的详细表示,同时模型还生成置信度图以评估重建的可靠性。
项目官网:https://fast3r-3d.github.io/arXiv技术论文:https://arxiv.org/pdf/2501.13928
机器人视觉:Fast3R能快速处理大量图像并重建3D场景,机器人可以通过多视角的图像输入,快速重建周围环境的3D模型,更好地规划路径、识别障碍物并执行任务。增强现实(AR):在增强现实应用中,Fast3R可以实时处理多个视角的图像,快速生成高精度的3D场景模型。虚拟现实(VR):Fast3R能高效地从多视角图像中重建出高精度的3D场景,通过快速处理大量图像,Fast3R可以生成逼真的3D环境,让用户在虚拟世界中获得更真实的视觉体验。文化遗产保护:Fast3R可以用于文化遗产的数字化重建。通过多视角拍摄文物或古迹,Fast3R能快速生成高精度的3D模型,便于文物的保护、研究和展示。自动驾驶:在自动驾驶领域,Fast3R可以处理车辆摄像头捕获的多视角图像,快速重建周围环境的3D模型。

快速创建交互式AI,支持自定义问答

“适用于需要快速建立自助客服的企业,包括电商、SaaS软件、网络服务等。”
小明使用FrequentlyAskedAI在一个月内制作了一个包含500个问题的智能问答机器人,嵌入到他的在线商店,每天可以回答超过2000个顾客提问,大大降低了人工客服负担。
小红是一名程序员,使用FrequentlyAskedAI轻松创建了一个代码常见问题解答机器人,内置了300个开发相关问题,放在他的博客上,能够过滤掉很多重复提问,提高工作效率。
小蓝的SaaS软件使用FrequentlyAskedAI快速生成了客户常见问题自助提问机器人,集成到产品内,大大减少了每天需要人工回复的问题数量,客户满意度提高了20%。
自定义问答
情感交互
多语言支持
https://www.frequentlyaskedai.com/
小编发现FrequentlyAskedAI网站非常受用户欢迎,请访问FrequentlyAskedAI网址入口试用。