
VideoWorld是什么
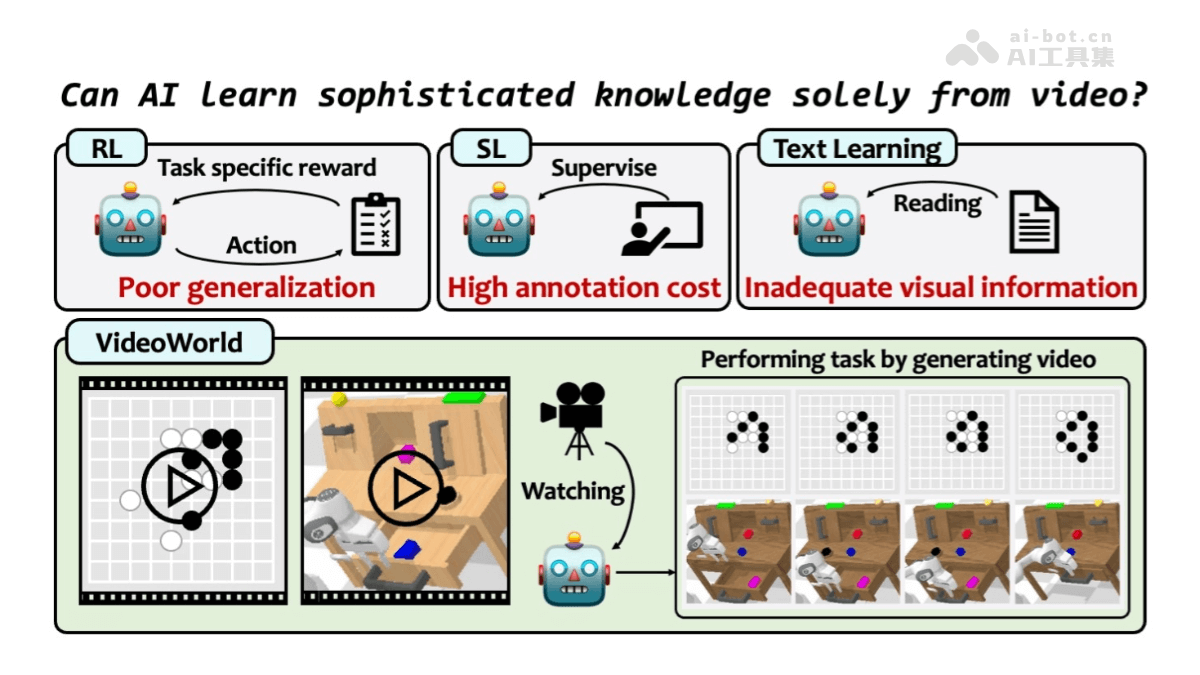
VideoWorld是北京交通大学、中国科学技术大学和字节跳动合作开展的一项研究项目,探索深度生成模型是否能仅通过未标注的视频数据学习复杂的知识,包括规则、推理和规划能力。该项目的核心是自回归视频生成模型,通过观察视频来获取知识,不依赖于传统的文本或标注数据。
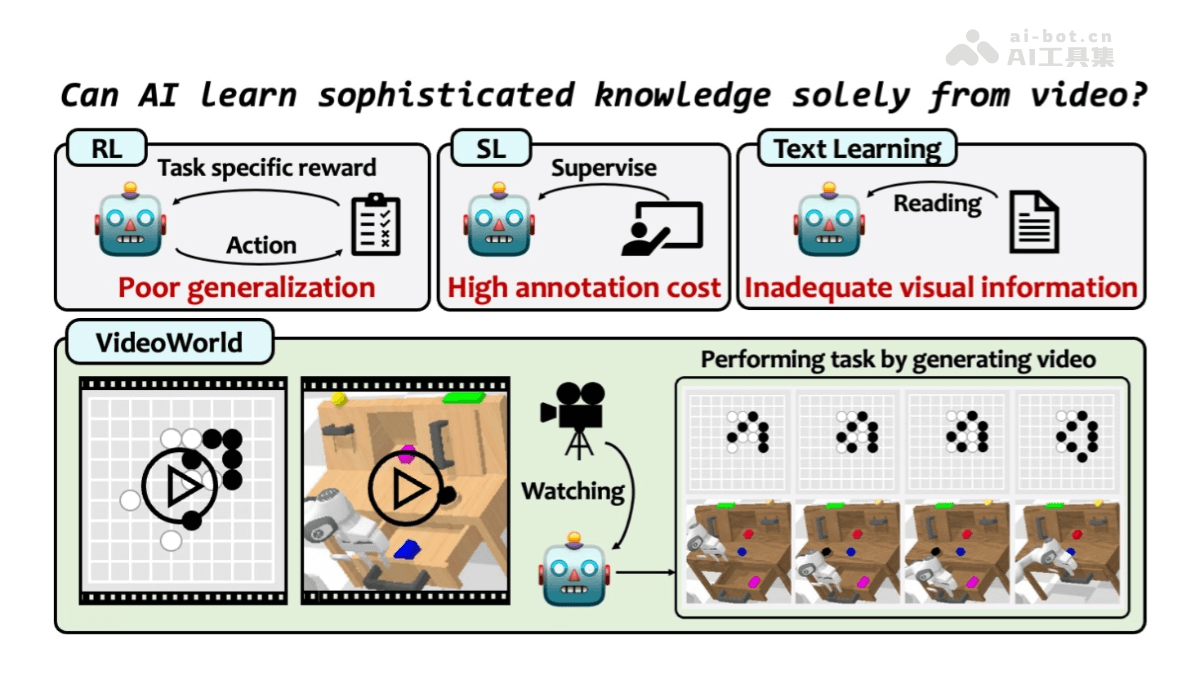
VideoWorld的主要功能
从未标注视频中学习复杂知识:VideoWorld 能仅通过未标注的视频数据学习复杂的任务知识,包括规则、推理和规划能力,无需依赖语言指令或标注数据。自回归视频生成:使用 VQ-VAE 和自回归 Transformer 架构,VideoWorld 可以生成高质量的视频帧,通过生成的视频帧推断出任务相关的操作。长期推理和规划:在围棋任务中,VideoWorld 能进行长期规划,选择最佳落子位置并击败高水平的对手(如 KataGo-5d)。 在机器人任务中,VideoWorld 能够规划复杂的操作序列,完成多种机器人控制任务。跨环境泛化能力:VideoWorld 能在不同的任务和环境中迁移所学的知识,表现出良好的泛化能力。 紧凑的视觉信息表示:LDM 将冗长的视觉信息压缩为紧凑的潜在代码,减少了信息冗余,提高了学习效率。 这种紧凑表示使模型能够更高效地处理复杂的视觉动态,支持长期推理和决策。无需强化学习的自主学习:VideoWorld 不依赖于传统的强化学习方法(如搜索算法或奖励机制),而是通过纯视觉输入自主学习复杂的任务。高效的知识学习与推理:VideoWorld 在围棋任务中达到了 5 段专业水平(Elo 2317),仅使用 3 亿参数,展示了其高效的知识学习能力。 在机器人任务中,VideoWorld 的任务成功率接近 oracle 模型,表现出高效推理和决策的能力。视觉信息的深度理解:VideoWorld 能通过生成的视频帧和潜在代码,理解复杂的视觉信息,支持任务驱动的推理和决策。支持多种任务类型:VideoWorld 不仅适用于围棋和机器人控制任务,还具有扩展到其他复杂任务的潜力,如自动驾驶、智能监控等领域。
VideoWorld的技术原理
VQ-VAE(矢量量化-变分自编码器):用于将视频帧编码为离散的 token 序列。VQ-VAE 通过矢量量化将连续的图像特征映射到离散的码本(codebook)中,生成离散的表示。自回归 Transformer:基于离散 token 序列进行下一个 token 的预测。Transformer 架构利用自回归机制,根据前面的帧预测下一帧,从而生成连贯的视频序列。潜在动态模型(LDM):引入 LDM,将多步视觉变化压缩为紧凑的潜在代码,提高知识学习的效率和效果。LDM 能捕捉视频中的短期和长期动态,支持复杂的推理和规划任务。视频生成与任务操作的映射: 在生成视频帧的基础上,VideoWorld 进一步通过逆动态模型(Inverse Dynamics Model, IDM)将生成的视频帧映射为具体的任务操作。 IDM 是一个独立训练的模块,通常由多层感知机(MLP)组成,能根据当前帧和生成的下一帧预测出相应的动作。数据驱动的知识学习:VideoWorld 通过大规模的未标注视频数据进行学习,减少了对人工标注数据的依赖,降低了数据准备的成本。
VideoWorld的项目地址
项目官网:https://maverickren.github.io/VideoWorldGitHub仓库:https://github.com/bytedance/VideoWorldarXiv技术论文:https://arxiv.org/pdf/2501.09781
VideoWorld的应用场景
自动驾驶:通过车载摄像头的视频输入,VideoWorld 可以学习道路环境的动态变化,识别交通标志、行人和障碍物。智能监控:通过观察监控视频,VideoWorld 可以学习正常和异常行为的模式,实时检测异常事件。故障检测:通过观察生产过程的视频,VideoWorld 可以学习正常和异常状态的模式,实时检测故障。游戏 AI:需要模型能根据游戏环境生成合理的操作,与玩家或其他 AI 对抗。通过观察游戏视频,VideoWorld 可以学习游戏规则和环境动态。故障检测:通过观察生产过程的视频,VideoWorld 可以学习正常和异常状态的模式,实时检测故障。