

XGenTools.io官网
探索AI工具和应用的目录

XGenTools.io简介
需求人群:
XGenTools适用于任何需要发现和使用人工智能工具和应用的人群。
产品特色:
智能搜索功能
手选AI工具集合
社区交流
XGenTools.io官网入口网址
https://xgentools.io
小编发现XGenTools.io网站非常受用户欢迎,请访问XGenTools.io网址入口试用。
探索AI工具和应用的目录
XGenTools适用于任何需要发现和使用人工智能工具和应用的人群。
智能搜索功能
手选AI工具集合
社区交流
https://xgentools.io
小编发现XGenTools.io网站非常受用户欢迎,请访问XGenTools.io网址入口试用。

LineArt是吉林大学、瑞典皇家理工学院、东京工业大学等机构推出的,无需训练的高质量设计绘图外观迁移框架,能将复杂外观特征转移到详细的设计图纸上,辅助设计和艺术创作。LineArt基于模拟人类层次化的视觉认知过程,整合艺术经验指导扩散模型,生成高保真度的图像,同时精准保留设计图纸的结构细节。LineArt包含两个核心阶段:首先是多频线融合模块,补充输入设计图纸的详细结构信息;其次是分为基础层塑造和表层着色的两部分绘画过程,分别处理光照和纹理特征。LineArt框架无需精确的3D建模或网络训练,便于设计任务的执行,在实验中展现出优于现有最先进方法的性能。

高保真度外观转移:将参考照片中的复杂外观特征(如材质、纹理、光照等)准确地转移到设计图纸上,让生成的图像在视觉上与参考照片高度一致。保持结构细节:在转移外观特征的过程中,精准保留设计图纸的细部结构,避免细节丢失或变形,确保设计图纸的原有意图得到充分体现。无需精确3D建模和网络训练:省去传统方法中所需的精确3D建模、物理属性规范或大规模网络训练过程,降低设计任务的复杂性和成本,提高设计效率。支持设计和艺术创作:为设计师和艺术家提供强大的工具,快速生成具有特定外观效果的设计图纸预览,帮助他们直观地评估设计效果,选择最合适的材料组合,加速设计迭代过程。
多频线融合模块:受视觉表示理论的启发,将输入的设计图纸补充为包含三个层次信息的理想草图。三个层次分别是:连续的单线用于区域划分,双线强调局部细节,及离散的软边缘点集表示隐含的空间梯度和纹理信息。多层次的视觉信息补充,为后续的扩散模型提供了丰富的结构细节,有助于生成更准确、真实的图像。基础层塑造和表层着色的两部分绘画过程:基础层塑造:从参考图像中分解出亮度控制因子,模拟油画中的底涂过程。基于亮度控制因子提供初始的明暗对比和结构形状,为后续的光照效果和纹理生成奠定基础。基于影响初始噪声分布的均值和方差,控制生成结果的整体亮度,建立生成图像与参考图像之间的软链接,让生成图像的光照属性与参考图像相匹配。表层着色:将参考图像分解得到的纹理图进行全局编码,然后选择性地注入到U – net架构的特定注意力层中,模拟油画中的透明层着色过程。这一过程基于解耦的交叉注意力机制整合文本特征、内容特征和外观特征,让合成的纹理图像引导外观生成,用软边缘作为高频引导,确保生成结果与纹理模式对齐,促进自然的布局变化,实现精确的材质嵌入和外观特征转移。知识引导的结构保持和外观转移:LineArt将人类绘画知识和视觉认知过程融入到图像生成中。分析输入草图的三个层次,将突出特征处理为双线,物体块的划分和几何边缘作为单线视觉表示,离散的低级视觉特征(软边缘)用在引导空间梯度表示和后续纹理生成,准确再现空间关系并适配物体的高频纹理。在外观转移方面,借鉴古典油画的“Imprimatura”技法,将绘画过程分为底涂和罩染两个阶段,分别处理隐含的图像信息(如光照、照明和阴影反射)及与纹理和颜色相关的特征,实现高保真度的外观转移效果。
项目官网:https://meaoxixi.github.io/LineArt/arXiv技术论文:https://arxiv.org/pdf/2412.11519v1
工业设计:用在产品外观设计预览和设计迭代加速,与不同材质纹理结合,快速生成逼真效果,优化产品设计。室内设计:实现家具材质搭配和空间效果模拟,帮助设计师选择合适材质,提升室内设计整体风格和质感。服装设计:展示服装面料效果和款式与材质搭配,为面料选择和图案设计提供参考,增强服装设计创新性和竞争力。建筑设计:模拟建筑外观材质和细节设计,评估建筑与环境协调性,优化建筑设计方案,提升建筑品质。动画与游戏设计:应用于角色设计和场景设计,生成逼真角色形象和场景效果预览,提升视觉体验和沉浸感。

全能 AI 助手,满足您的各种需求

“适用于各种工作和生活场景,可以用于聊天互动、创作辅助、绘画辅助、私人助理等”
与 ChatGAi 进行聊天互动,获取有趣的回答
使用 ChatGAi 的绘画助理功能,获得绘画灵感
将 ChatGAi 作为个人助理,帮助管理日程安排
Ai 聊天
Ai 创作
Ai 绘画助理
Ai 私人助理
https://chatgai.lovepor.cn/
小编发现ChatGAi网站非常受用户欢迎,请访问ChatGAi网址入口试用。

SynthLight 是耶鲁大学和 Adobe Research 联合推出的基于扩散模型的人像重照明技术,通过模拟不同光照条件下的合成数据进行训练,能将人像照片重新渲染为具有全新光照效果的图像,比如添加高光、阴影或调整整体光照氛围。核心在于基于物理基础的渲染引擎生成合成数据集,通过多任务训练和分类器引导的扩散采样策略,弥合合成数据与真实图像之间的差异,实现对真实人像的高质量重照明。

肖像重光照:通过环境光照图对肖像进行重光照处理,生成逼真的光照效果,如自然的高光、投影和漫反射。多任务训练:基于无光照标签的真实人像进行多任务训练,提升模型的泛化能力,能处理各种真实场景。推理时间采样:采用基于无分类器指导的扩散采样程序,在推理阶段保留输入肖像的细节,确保生成的光照效果自然且细腻。物理渲染引擎:使用物理渲染引擎生成合成数据集,模拟不同光照条件下的光照转换,提供高质量的光照效果。通用性:尽管仅使用合成数据进行训练,SynthLight 能很好地泛化到真实场景,包括半身像和全身像。
将重光照视为重新渲染问题:SynthLight 将图像重光照定义为一个重新渲染的过程,通过改变环境光照条件来调整像素的渲染效果。基于物理的渲染引擎与合成数据集:技术基于物理的渲染引擎(Physically-Based Rendering Engine)生成合成数据集。通过在不同光照条件下对3D头部模型进行渲染,模拟真实光照条件下的像素变化。多任务训练策略:SynthLight 采用了多任务训练方法,利用没有光照标签的真实人像进行训练。通过结合真实图像和合成图像的训练,帮助模型更好地适应真实场景,减少合成数据与真实图像之间的域差距。基于无分类器指导的扩散采样:在推理阶段,SynthLight 使用基于无分类器指导的扩散采样程序(Classifier-Free Guidance)。利用输入的人像细节来更好地保留图像的纹理和特征,同时生成逼真的光照效果。扩散模型的优势:扩散模型通过逐步添加噪声并学习去噪过程来生成图像。SynthLight 基于这一特性,生成高质量的光照效果,包括镜面高光、阴影和次表面散射等。
项目官网:https://vrroom.github.io/synthlightarXiv技术论文:https://arxiv.org/pdf/2501.09756
人像摄影后期处理:SynthLight 可以对真实人像照片进行重光照处理,生成逼真的光照效果,如自然的高光、阴影和漫反射。虚拟场景渲染与合成:通过模拟不同的光照条件,SynthLight 可以将真实人像与虚拟场景无缝融合,生成高质量的合成图像。游戏开发与角色设计:在游戏开发中,SynthLight 可以用于快速调整角色的光照效果,适应不同的场景和环境,节省时间和成本。广告与商业图像制作:在广告和商业图像制作中,SynthLight 能快速生成多种光照条件下的图像,帮助设计师快速探索不同的视觉效果,提升工作效率。

玩一个超级有趣的聊天游戏!试试看能否辨别出你正在与人类还是AI机器人交流。你能分辨出谁是谁吗?

适用于喜爱挑战和有趣游戏的用户,可以用于娱乐和消遣。
在游戏中与朋友一起竞猜对方是人还是机器人
挑战自己的判断力,看看能否准确判断出对方的身份
与陌生人聊天,寻找有趣的对话和交流
与人类或AI机器人进行聊天
通过聊天内容判断对方是人还是机器人
享受有趣的社交图灵游戏
https://humanornot.so
小编发现Human or Not网站非常受用户欢迎,请访问Human or Not网址入口试用。

X-Dyna 是基于扩散模型的动画生成框架,基于驱动视频中的面部表情和身体动作,将单张人类图像动画化,生成具有真实感和环境感知能力的动态效果。核心是 Dynamics-Adapter 模块,能将参考图像的外观信息有效地整合到扩散模型的空间注意力中,同时保留运动模块生成流畅和复杂动态细节的能力。
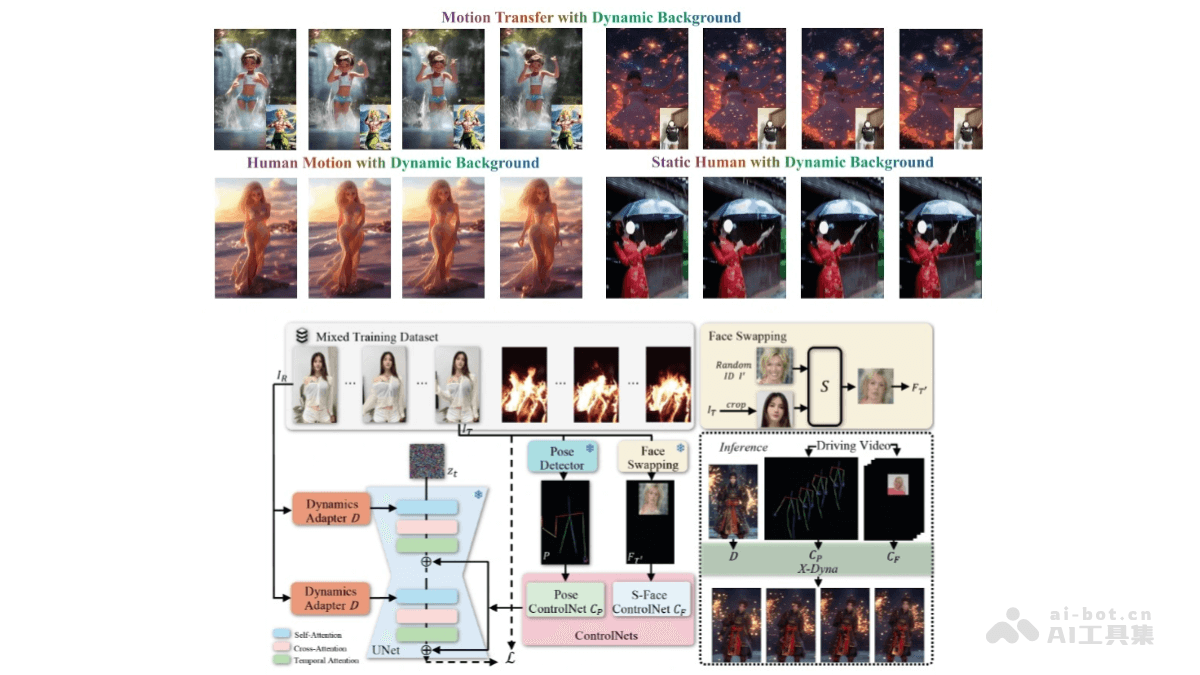
单张图像动画化:X-Dyna 能将单张人类图像通过面部表情和身体动作的驱动,生成具有真实感和环境感知能力的动态视频。面部表情和身体动作控制:工具通过 Dynamics-Adapter 模块,将参考图像的外观信息整合到扩散模型中,同时保留运动模块的动态细节生成能力。还支持面部表情的身份解耦控制,能实现准确的表情转移。混合数据训练:X-Dyna 在人类动作视频和自然场景视频的混合数据集上进行训练,能同时学习人类动作和环境动态。高质量动态细节生成:通过轻量级的 Dynamics-Adapter 模块,X-Dyna 可以生成流畅且复杂的动态细节,适用于多种场景和人物动作。零样本生成能力:X-Dyna 不依赖于目标人物的额外数据,可以直接从单张图像生成动画,无需额外的训练或数据输入。
扩散模型基础:X-Dyna 基于扩散模型(Diffusion Model),通过逐步去除噪声来生成图像或视频。Dynamics-Adapter 模块:X-Dyna 的核心是 Dynamics-Adapter,轻量级模块,用于将参考图像的外观信息整合到扩散模型的空间注意力中。具体机制如下:参考图像整合:Dynamics-Adapter 将去噪后的参考图像与带噪声的序列并行输入到模型中,通过可训练的查询投影器和零初始化的输出投影器,将参考图像的外观信息作为残差注入到扩散模型中。保持动态生成能力:该模块确保扩散模型的空间和时间生成能力不受影响,从而保留运动模块生成流畅和复杂动态细节的能力。面部表情控制:除了身体姿态控制,X-Dyna 引入了一个局部控制模块(Local Control Module),用于捕获身份解耦的面部表情。通过合成跨身份的面部表情补丁,隐式学习面部表情控制,实现更准确的表情转移。混合数据训练;X-Dyna 在人类动作视频和自然场景视频的混合数据集上进行训练。使模型能同时学习人类动作和环境动态,生成的视频不仅包含生动的人类动作,还能模拟自然环境效果(如瀑布、雨、烟花等)。

DeepSeek-R1是杭州深度求索人工智能基础技术研究有限公司发布的高性能AI推理模型,对标OpenAI的o1正式版。模型通过大规模强化学习技术进行后训练,仅需极少量标注数据,便能在数学、代码和自然语言推理等任务上取得卓越表现。DeepSeek-R1遵循MIT License开源,支持模型蒸馏,训练其他模型。
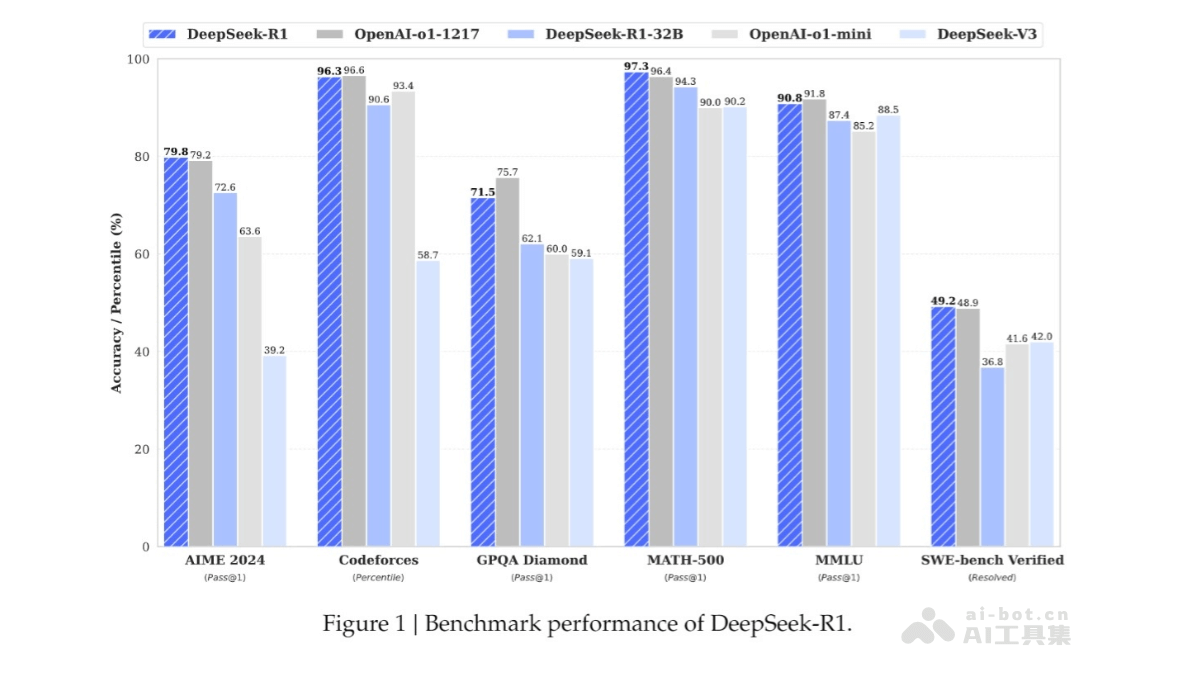
高性能推理能力:在数学、代码和自然语言推理等任务上表现出色,性能与 OpenAI 的 o1 正式版相当。

与朋友一起使用AI

“用户可以与朋友一起使用AI进行群聊,分享各种有趣的话题和信息。”
与朋友一起创建群聊,AI加入对话
邀请同学共同使用Iceberg进行分享和交流
与AI一起参与有趣的话题讨论
与朋友创建群聊
邀请朋友加入
与AI进行聊天
https://apps.apple.com/us/app/iceberg-group-chats-with-ai/id6470951246
小编发现Iceberg网站非常受用户欢迎,请访问Iceberg网址入口试用。

免注册的AI聊天机器人

ChatGPT Online适用于需要快速获取答案、翻译文本或用外语进行对话的场景。
通过聊天与聊天机器人对话
翻译语言
访问知识库
https://gptonline.ai
小编发现ChatGPT Online网站非常受用户欢迎,请访问ChatGPT Online网址入口试用。

k1.5 是月之暗面Kimi推出的最新多模态思考模型,具备强大的推理和多模态处理能力。模型在 short-CoT(短链思维)模式下,数学、代码、视觉多模态和通用能力大幅超越了全球范围内短思考 SOTA 模型 GPT-4o 和 Claude 3.5 Sonnet,领先幅度高达 550%。在 long-CoT(长链思维)模式下,k1.5 的性能达到了 OpenAI o1 正式版的水平,成为全球范围内首个达到这一水平的多模态模型。
k1.5 的设计和训练包含四大关键要素:长上下文扩展、改进的策略优化、简洁的框架和多模态能力。通过扩展上下文窗口至 128k 和部分展开技术,模型在推理深度和效率上显著提升。k1.5 通过 long2short 技术,将长链思维的优势迁移到短链思维模型中,进一步优化性能。
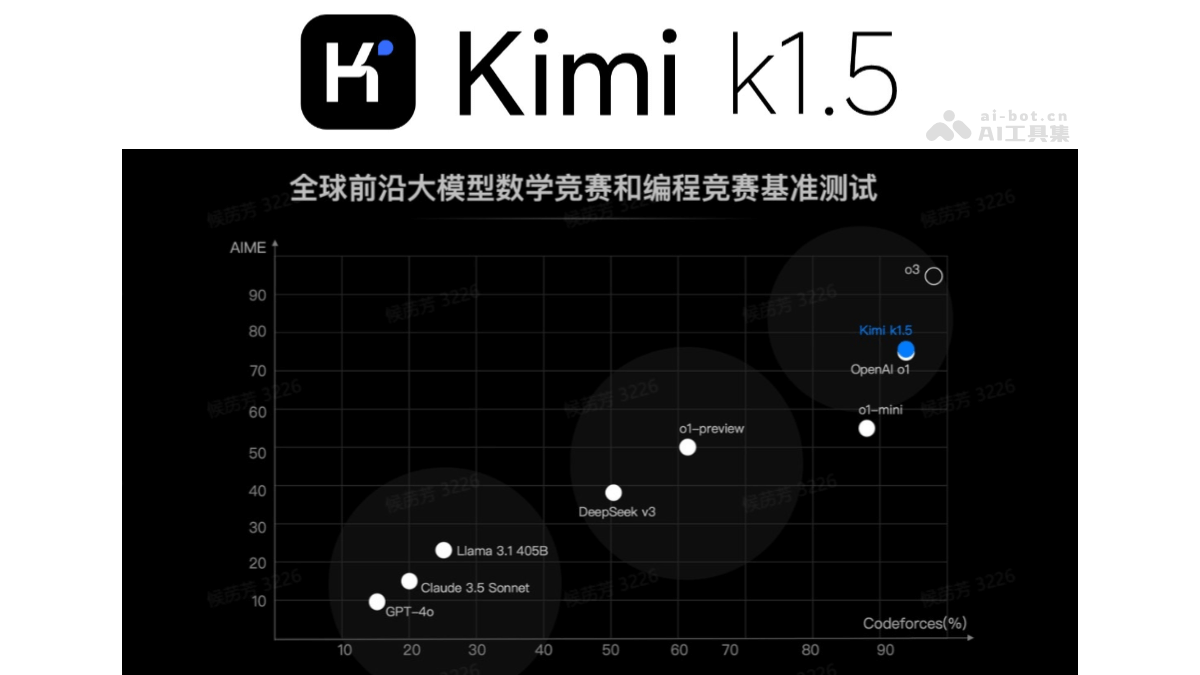
多模态推理能力:k1.5 能同时处理文本和视觉数据,具备联合推理能力,适用于数学、代码和视觉推理等领域。