百聆是什么
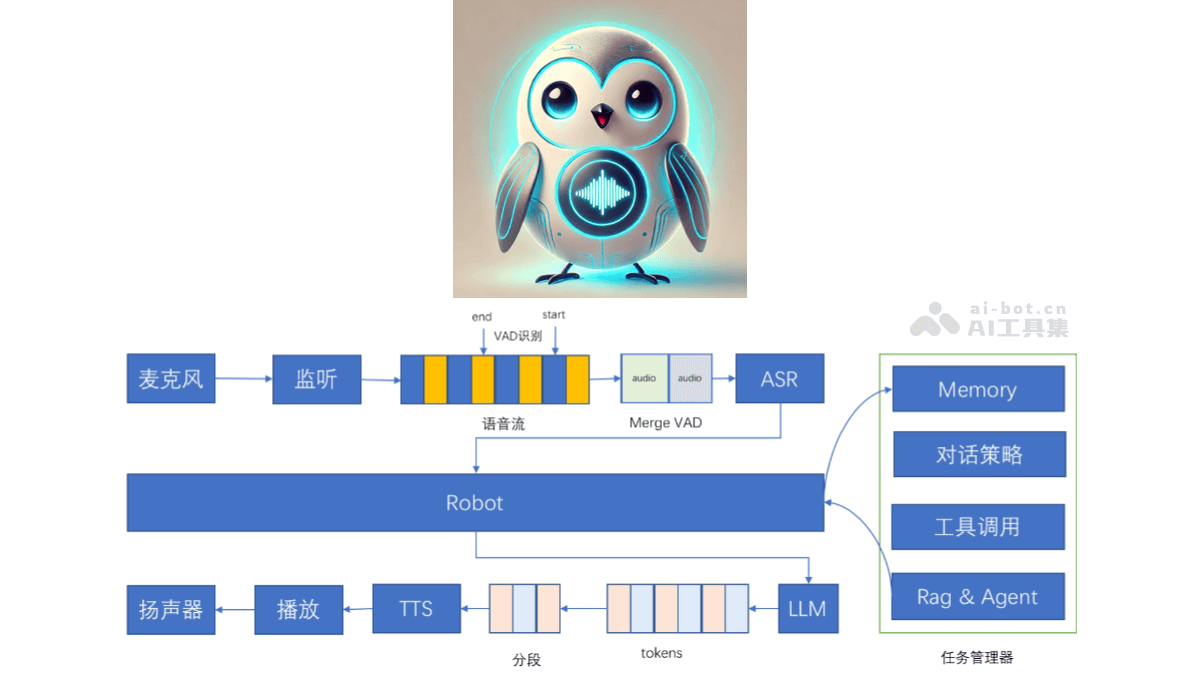
百聆(Bailing)是开源的语音对话助手,基于语音识别(ASR)、语音活动检测(VAD)、大语言模型(LLM)和语音合成(TTS)技术实现与用户的自然语音对话,实现类GPT-4o的对话效果。百聆无需GPU即可运行,端到端时延低至800ms,适用于各种边缘设备和低资源环境。百聆具备高效开源模型、无需GPU、模块化设计、支持记忆功能、支持工具调用、支持任务管理等项目特点,提供高质量的语音对话体验。
百聆的主要功能
语音输入与识别:准确地将用户的语音输入转换为文本,为后续的对话处理提供基础。语音活动检测:过滤掉无效的音频片段,对有效的语音部分进行处理,提高语音识别的效率和准确性,避免对背景噪音等非目标语音的误识别。智能对话生成:对用户输入的文本进行深度理解和处理,生成自然、流畅且富有逻辑的文本回复,为用户提供智能、贴心的对话体验。语音输出与合成:将生成的文本回复转换为自然、逼真的语音,播放给用户,让用户基于听觉获取信息,实现完整的语音交互闭环。支持打断:具备灵活的打断策略,识别用户的关键字和语音打断行为,及时响应用户的即时反馈和控制指令。记忆功能:拥有持续学习的能力,能记忆用户的偏好、历史对话等信息,为用户提供个性化的互动体验。工具调用:支持灵活集成外部工具,用户用语音指令直接请求信息或执行操作,如查询天气、搜索新闻、设置提醒等。任务管理:高效地管理用户的任务,包括跟踪任务进度、设置提醒及提供动态更新等。
百聆的技术原理
语音识别(ASR):基于FunASR技术,将用户的语音信号转换为文本数据。涉及到对语音信号的采集、预处理、特征提取及模式匹配等步骤,用深度学习算法等技术手段,识别出语音中的词汇和语义信息,为后续的对话处理提供文本输入。语音活动检测(VAD):基于silero-vad技术,对语音信号进行实时监测和分析,判断语音片段中是否包含有效的语音活动。分析语音信号的特征,如能量、过零率等,区分出语音和非语音部分,只对有效的语音片段进行后续处理,提高系统的效率和准确性。大语言模型(LLM):deepseek作为核心的大语言模型,对ASR模块输出的文本进行处理。模型基于大量的文本数据进行训练,具备强大的语言理解和生成能力。理解用户输入文本的语义,结合上下文信息,运用自然语言处理技术,生成准确、自然且富有逻辑的文本回复,为用户提供智能的对话内容。语音合成(TTS):用edge-tts等技术,将LLM生成的文本回复转换为语音信号。这一过程包括文本分析、韵律预测、语音合成等步骤,基于深度学习模型等技术,模拟人类的语音发音特点,生成自然、流畅且富有表现力的语音,让用户用听觉获取信息,实现语音交互的输出。
百聆的项目地址
GitHub仓库:https://github.com/wwbin2017/bailing
百聆的应用场景
智能家居控制:用语音指令操控家电设备,如开关灯、调节空调温度等,能切换预设的家居场景模式,如“观影模式”“睡眠模式”,提升家居生活的便捷性和舒适度。个人助理服务:帮助用户管理日程,提醒会议、约会等安排;查询天气、新闻、股票等信息,进行整理总结。汽车智能交互:作为车载语音助手,实现导航设置、音乐播放、电话拨打等操作,提高驾驶安全性和便利性;查询车辆信息,如油量、里程,控制车辆功能,如座椅加热、空调风速调节等。教育辅助工具:为学生提供在线学习辅导,解答学习问题,帮助理解知识;在语言教学中模拟场景进行对话练习,提供发音和语调反馈,增强学习效果。办公辅助应用:在会议中记录和整理会议内容,生成关键信息总结和待办事项清单。