XMusic是什么
XMusic是腾讯多媒体实验室自主研发的AI通用作曲框架。用户只需上传视频、图片、文字、标签、哼唱等任意内容,XMusic能生成情绪、曲风、节奏可控的高质量音乐。基于自研的多模态和序列建模技术,可将提示词内容解析至符号音乐要素空间,以此为控制条件引导模型生成丰富、精准、动听的音乐,达到商用级的音乐生成能力要求。XMusic适用于视频剪辑配乐、商超会场环境音乐选择以及互动娱乐、辅助创作、音乐教育、音乐治疗等诸多场景,能大幅降低音乐创作门槛,随时随地实现AI辅助创作,打造个人专属的“行走的音乐库”。
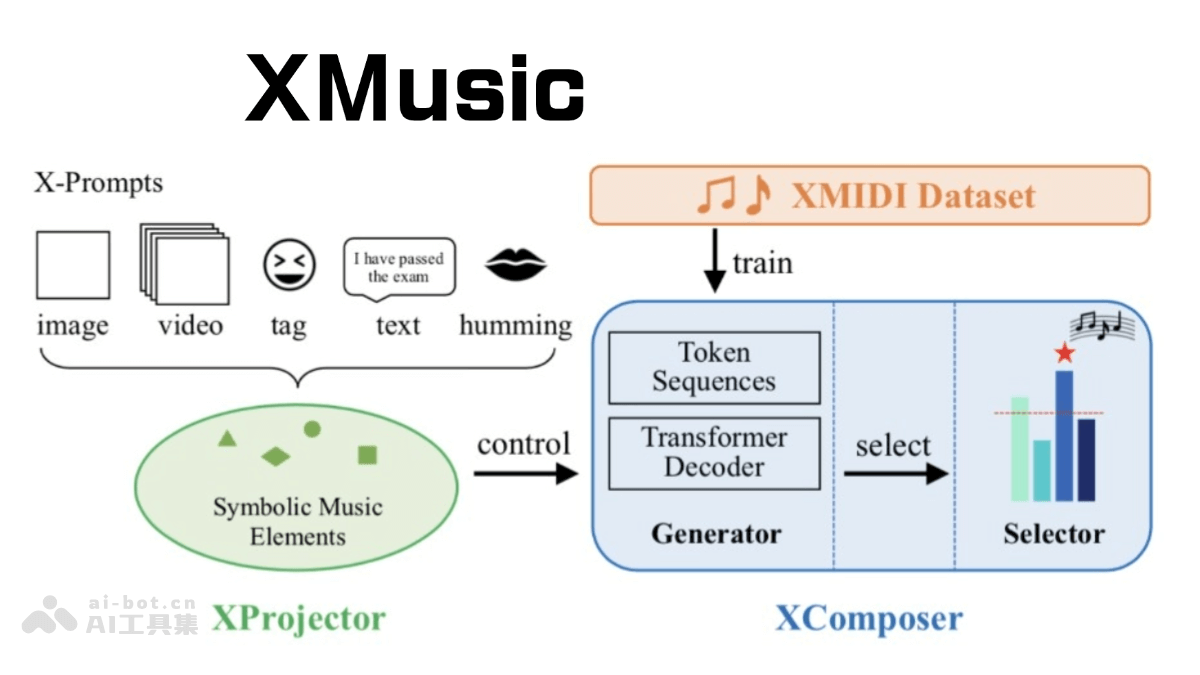
XMusic的主要功能
多模态输入生成音乐:支持图片、文字、视频、标签、哼唱等多种模态内容作为提示词,生成情感可控的高质量音乐。例如输入“逗趣横生,让人捧腹大笑”的描述,XMusic就会生成一段节奏俏皮、旋律欢快的音乐。情绪、曲风、节奏可控:用户可以根据自己的需求,生成具有特定情绪、曲风、节奏的音乐,满足不同场景下的音乐使用需求。商用级音乐生成能力:基于自研的多模态和序列建模技术,XMusic可以将提示词内容解析至符号音乐要素空间,并以此为控制条件引导模型生成丰富、精准、动听的音乐,达到商用级的音乐生成能力要求。
XMusic的技术原理
核心框架:基于本地化部署的Transformers算法框架,该框架具有强大的自然语言处理能力和跨模态学习能力,为音乐生成提供了坚实基础。核心组件:XProjector:将各种形式的提示(如图像、视频、文本、标签和哼唱)解析为符号音乐元素(如情感、流派、节奏和音符)在投影空间内生成匹配的音乐。XComposer:包含生成器和选择器。生成器基于创新的符号音乐表示生成可控制情感且旋律优美的音乐;选择器通过构建涉及质量评估、情感识别和流派识别任务的多任务学习方案来识别高质量的符号音乐。 运行机制:分为解析、生成、筛选三个阶段。解析阶段基于自然语言处理和图像识别技术,对用户输入的提示词进行分析并映射至符号音乐要素投影空间;生成阶段,生成器将音乐要素映射至符号音乐表征序列,解码器根据这些表征序列生成匹配的音乐旋律和节奏;筛选阶段,筛选器对生成的批量音乐进行质量评估,筛选出质量最高、最符合用户需求的音乐。
XMusic的的项目地址
项目官网:https://xmusic-project.github.ioarXiv技术论文:https://arxiv.org/pdf/2501.08809
XMusic的的应用场景
互动娱乐:在互动娱乐场景中,可根据用户的互动行为或输入生成相应的音乐,增强互动体验。辅助创作:为音乐创作者提供灵感和辅助,帮助其快速生成音乐素材,提高创作效率。音乐教育:音乐课的老师可使用XMusic生成多样的节拍、节奏、音高练习曲目,并结合实际教学场景,发挥AI生成音乐的教学辅助能力。音乐治疗:根据治疗需求生成相应的音乐,辅助音乐治疗过程。