

Radiant AI官网
高质量医学信息的聊天机器人

Radiant AI简介
需求人群:
主要用于临床医生和医学学习者
产品特色:
为医疗专业人员提供高质量的医学信息
通过检索和生成模型生成答案
使用OSLER平台LLM框架构建
Radiant AI官网入口网址
https://www.radiantai.health
小编发现Radiant AI网站非常受用户欢迎,请访问Radiant AI网址入口试用。
高质量医学信息的聊天机器人
主要用于临床医生和医学学习者
为医疗专业人员提供高质量的医学信息
通过检索和生成模型生成答案
使用OSLER平台LLM框架构建
https://www.radiantai.health
小编发现Radiant AI网站非常受用户欢迎,请访问Radiant AI网址入口试用。

Luma Ray2 是 Luma AI 推出的最新视频生成模型,Ray2 基于 Luma 新的多模态架构训练后展现出先进功能,该架构的计算能力是 Ray1 的 10 倍。能生成快速连贯的运动、超逼真的细节和逻辑事件序列。能在短短 10 秒内根据文本和图像提示生成高质量的视频内容。与前代模型相比,Ray2 的视频生成能力更强大,生成视频的最长时长从 5 秒钟延长到了 1 分钟,用户能更充分地展现创意。创建具有自然、连贯运动的逼真视觉效果。对文本指令有很强的理解能力,可以理解人、动物和物体之间的互动,创建出连贯且物理上准确的角色。Ray2 现在支持文本转视频生成功能,即将推出图像转视频、视频转视频和编辑功能。

文本生成视频:用户可以输入文本描述,生成 5 到 10 秒的短视频。例如,可以生成一个人在南极暴风雪中奔跑的场景以及一位芭蕾舞者在北极冰面上表演的画面,视频中的动作看起来生动流畅,且动作速度远超其他竞争对手的 AI 生成视频。先进的电影摄像技术:生成的视频片段展现先进的电影摄像技术、流畅的运动画面和引人入胜的戏剧效果。从大全景镜头到近距离特写,模型的动态运镜效果可以烘托视觉叙事,赋予角色连贯的生命力。更长的视频生成时长:与前代模型相比,Ray2 生成视频的最长时长从 5 秒钟延长到了 1 分钟,用户能更充分地展现创意。
多模态转换器架构:Luma Ray2 建立在多模态转换器架构上,能处理和融合来自不同模态的数据(如文本、图像、视频等),实现更强大的视频生成能力。多模态转换器架构通过以下步骤实现数据的融合和处理:数据融合:将来自不同模态的数据进行融合,提取出更全面、更丰富的特征表示。跨模态理解:实现不同模态数据之间的相互理解和转换,将文本描述转换为图像,或将图像转换为3D模型。提高模型性能:通过基于多模态数据的互补信息,提高模型的性能,提高3D重建的准确性、生成更逼真的3D内容。
项目官网:https://lumalabs.ai/ray
电影和电视剧制作:Luma Ray2 可以生成逼真的 3D 场景和特效,为电影和电视剧带来更加震撼的视觉体验。视频内容创作:内容创作者可以用 Luma Ray2 生成高质量的视频片段,用于制作短视频、Vlog、纪录片等。广告制作:广告业者可以快速生成引人注目的广告内容,提高产品的市场竞争力。游戏内动画:生成游戏内的动画和特效,提升游戏的视觉效果和玩家体验。Luma Ray2 的多模态转换器架构能够理解人、动物和物体之间的互动,生成连贯且物理上准确的角色动画。教育视频:教育机构可以用 Luma Ray2 生成教育视频,用于在线课程、教学辅助材料等。

个人AI助手,学习、分享、提问

“个性化学习、内容创作、客户服务”
教育机构利用Kaya创建个性化学习AI助手
创作者利用Kaya生成交互式内容体验
企业利用Kaya构建智能客服代理
个性化学习
内容创作
客户服务
https://kaya.chat/
小编发现Kaya网站非常受用户欢迎,请访问Kaya网址入口试用。

RAIN(Real-time Animation Of Infinite Video Stream)是创新的实时动画解决方案,基于消费级硬件,如单个RTX 4090 GPU,实现无限视频流的实时动画化。核心在于高效地计算不同噪声水平和长时间间隔的帧标记注意力,同时去噪大量帧标记,以极低的延迟生成视频帧,保持视频流的长期连续性和一致性。RAIN通过引入少量额外的一维注意力块,对Stable Diffusion模型进行微调,能在几轮训练后,实时、低延迟地生成高质量、一致性的无限长视频流。在实时动画领域具有重大意义,为在线互动、虚拟角色生成等应用场景提供了强大的技术支持。
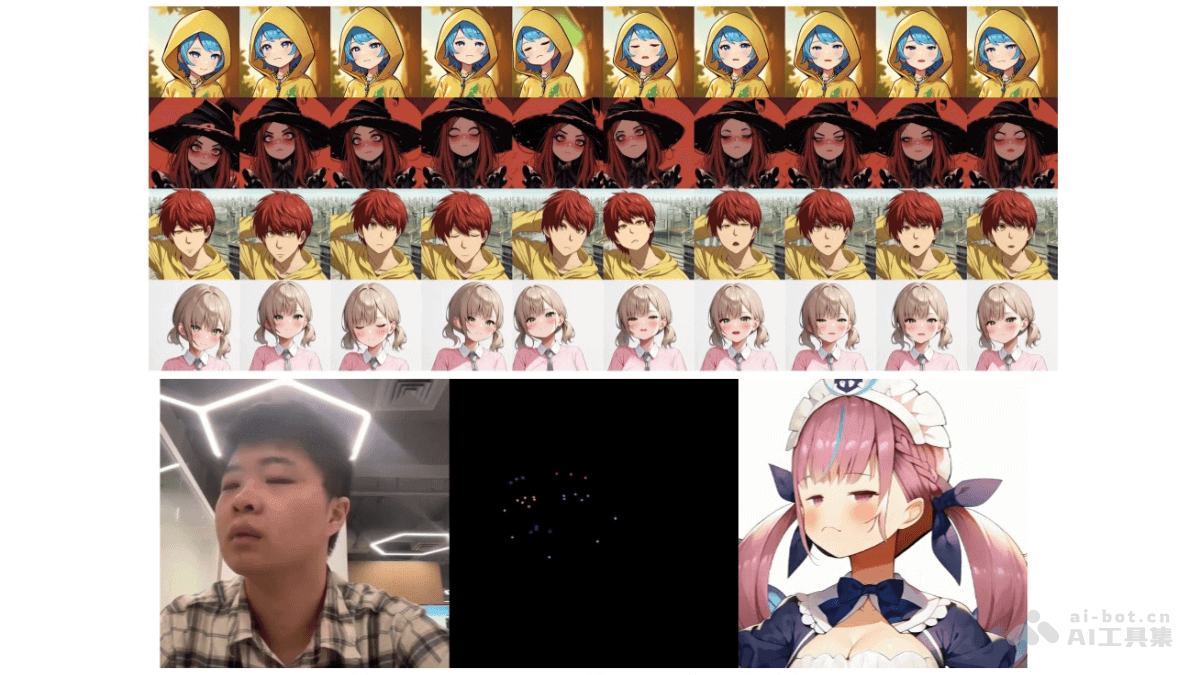
实时动画生成:能在消费级GPU上,如单个RTX 4090,以低延迟实时生成动画,突破了传统方法在生成速度和延迟上的限制,使动画内容能即时呈现,适用于需要实时互动的场景,如直播、在线会议等。无限视频流处理:打破了视频长度的限制,可以持续生成无限长的视频流,满足长时间直播或连续动画展示的需求,为创造连续、流畅的视觉体验提供了可能。高质量与一致性保障:通过在不同噪声水平和长时间间隔内高效计算帧标记注意力,同时去噪大量帧标记,确保生成的视频在视觉质量上保持高标准,同时维持长期的连续性和一致性,避免了画面的突兀变化和质量下降。模型微调与适配:对Stable Diffusion模型进行针对性微调,快速适应实时动画生成任务,仅需少量训练周期就能达到理想的生成效果,降低了模型训练成本和时间投入。
帧标记注意力机制:RAIN的核心在于高效计算不同噪声水平和长时间间隔的帧标记注意力。RAIN通过扩大StreamBatch的大小,将每p个连续的帧标记分配到具有相同噪声水平的去噪组中,逐步增加这些组的噪声水平。充分利用了硬件的计算潜力,允许模型在更长的帧标记序列上计算注意力,显著提高了生成视频流的一致性和连续性。去噪过程的优化:RAIN在去噪过程中引入了创新的方法。RAIN结合不同去噪组之间的长期注意力时,跨噪声水平的注意力计算可以有效地提高连续性和视觉质量。这种长期注意力和跨噪声水平注意力的协同作用,显著提升了动画的流畅性和视觉效果。一致性模型的应用:RAIN基于一致性模型(Consistency Model)来加速扩散模型的采样过程。一致性模型满足特定的数学条件,使模型能在一步中生成样本。通过一致性蒸馏损失函数,RAIN训练了能快速采样的模型,实现多步采样,提高采样效率。流扩散技术:RAIN借鉴了流扩散(Stream Diffusion)技术,将不同噪声水平的帧推入一个批处理中,充分利用GPU的批计算能力。参考机制:为保持角色的一致性,RAIN采用参考机制。通过预训练的2D UNet作为ReferenceNet,对参考图像进行推理,缓存空间注意力操作前的输入隐藏状态。两阶段训练策略:RAIN的训练采用两阶段策略。第一阶段,模型在来自同一视频的图像对上进行训练,同时训练参考网和姿势引导器以及去噪UNet。第二阶段,模型对视频帧添加噪声,根据特定的时间步长对运动模块进行微调,适应时间变化。这种训练策略使模型能接受流视频输入,处理无限长的视频。
项目官网:https://pscgylotti.github.io/pages/RAINGithub仓库:https://github.com/Pscgylotti/RAINarXiv技术论文:https://arxiv.org/pdf/2412.19489
虚拟角色互动:在游戏和虚拟现实(VR)/增强现实(AR)应用中,RAIN可以实时生成虚拟角色的动画,角色能根据玩家的动作和表情进行实时响应,增强沉浸感和互动性。动画制作:对于动画制作公司,RAIN可以作为辅助工具,快速生成动画草稿或预览,提高制作效率。虚拟主播:在直播平台上,RAIN可以生成虚拟主播的实时动画,虚拟主播可以根据主播的语音和表情进行实时反应,提供更加丰富和多样化的直播内容。在线教育:在在线教育平台中,RAIN可以生成虚拟教师的动画,使教学内容更加生动和形象。

与您的健康数据进行对话

“用户可以使用Watzie应用来直接与其健康数据进行交流,理解数据并做出更好的决策。”
用户可以通过Watzie应用直接与其健康数据进行交流,了解健康状况并获取个性化建议。
医疗保健机构可以利用Watzie应用帮助患者更好地理解其健康数据,提供更好的医疗建议。
健身教练可以利用Watzie应用与客户的健康数据进行交流,制定更科学的健身计划。
利用人工智能技术帮助用户理解健康数据
使用户能够更好地管理健康数据
注重隐私保护
https://watzie.com/
小编发现Watzie网站非常受用户欢迎,请访问Watzie网址入口试用。

Pipecat是开源的Python框架,专注于构建语音和多模态对话代理。基于内置的语音识别、文本转语音(TTS)和对话处理功能,简化AI服务的复杂协调、网络传输、音频处理和多模态交互,让开发者能专注于创造引人入胜的用户体验。Pipecat支持与多种流行的AI服务(如OpenAI、ElevenLabs等)灵活集成,采用管道架构,支持开发者用简单、可复用的组件构建复杂的应用。Pipecat基于帧的管道架构确保了实时处理能力,实现流畅的交互体验。

语音优先设计:内置语音识别、文本转语音(TTS)和对话处理功能。灵活集成:支持与流行的AI服务(如OpenAI、ElevenLabs等)配合使用。管道架构:基于简单、可复用的组件构建复杂应用。实时处理:基于帧的管道架构,实现流畅交互。生产就绪:支持企业级的WebRTC和WebSocket。
管道架构:Pipecat基于管道架构,将数据处理分解为多个阶段,每个阶段处理特定的任务。每个阶段是独立的模块,如语音识别模块、文本处理模块、TTS模块等。模块基于定义好的接口进行数据交换,确保系统的灵活性和可扩展性。实时处理:帧级处理:数据用帧的形式在管道中流动,每个帧包含一小段数据(如音频帧、文本帧等)。帧级处理方式确保数据处理的实时性,适用于实时对话和多模态交互。异步处理:使用异步编程模型(如Python的asyncio),确保数据处理的高效性和并发性。集成与扩展:插件机制:Pipecat支持插件机制,开发者能轻松添加对不同AI服务的支持。例如,安装特定的依赖包(如pipecat-ai[openai]),集成OpenAI的API。灵活的配置:基于配置文件(如.env文件),开发者能轻松配置各种参数,如API密钥、服务地址等,确保系统的灵活性和可配置性。
项目官网:https://github.com/pipecat-ai/pipecat
语音助手:用在智能家居控制、个人日程管理、娱乐互动等,提供便捷的语音操作和信息查询服务。企业服务:包括自动客服、客户反馈收集、销售和营销自动化,提升企业运营效率和客户满意度。教育与培训:作为智能辅导工具,辅助语言学习和学科辅导,及提供互动式在线培训课程。健康与医疗:提供健康咨询、症状查询、心理支持等服务,帮助用户管理健康和情绪。多模态应用:在视频会议中提供实时字幕和表情识别,在多媒体内容创作中辅助视频编辑和图像识别。

LinkAI提供智能对话、绘画等AI能力

“可用于客服问答、知识库问答、创意设计、游戏绘画、无代码应用开发等多种场景。”
用户可以通过语音或文本与LinkAI进行自然语言交互,提问常见问题获取答案
用户可以描述图像内容,LinkAI可自动生成对应的图片
企业可以通过LinkAI快速创建包含智能对话的客服应用
智能对话
AI绘画
知识库问答
语音交互
无代码应用创建
https://link-ai.tech/
小编发现Link.AI网站非常受用户欢迎,请访问Link.AI网址入口试用。

RealtimeSTT是开源的实时语音转文本库,专为低延迟应用设计。有强大的语音活动检测功能,可自动识别说话的开始与结束,通过WebRTCVAD和SileroVAD进行精准检测。同时支持唤醒词激活,借助Porcupine或OpenWakeWord检测特定唤醒词来启动。核心转录功能由Faster_Whisper实现,可将语音实时转换为文本,适用于语音助手、实时字幕等场景,为开发者提供了一种高效、易用的语音转文本解决方案,助力打造流畅的语音交互体验。

语音活动检测:精准识别说话时段能自动检测何时开始和停止说话,先使用WebRTCVAD进行初步的声音活动检测,再用SileroVAD进行更准确的验证,精准地识别出说话的起始和结束时间,避免无效的录音和转录,提高资源利用效率和转录准确性。实时转录:使用Faster_Whisper进行即时(GPU加速)转录,可将语音实时转换为文本,能第一时间获取语音内容的文本形式,满足实时交互、会议记录、实时字幕等对转录速度要求较高的场景需求。语音唤醒功能:支持Porcupine或OpenWakeWord进行唤醒词检测,通过检测指定的唤醒词来激活系统,使设备能在待机状态下被唤醒并开始工作,为语音助手等应用提供了便捷的启动方式,提升了用户体验。灵活的音频输入方式:可以使用麦克风实时录音进行转录,也可以通过feed_audio()方法输入预先录制好的音频块进行转录,为不同的使用场景和需求提供了灵活的音频输入选择。音频预处理:在转录前会对音频进行必要的预处理,如调整采样率等,确保音频格式符合转录模型的要求,提高转录的准确性和可靠性。实时输出文本:转录得到的文本能够实时输出,开发者可以通过定义处理函数来接收和处理这些文本,如直接打印显示、输入到文本框中等,方便与其他应用功能进行集成和拓展。支持多语言:具备多语言转录的能力,能识别和转录多种语言的语音,满足不同语言环境下的使用需求。
初步检测:使用WebRTCVAD进行初步的语音活动检测,能快速识别音频流中的语音段和非语音段,确定何时开始和停止录音。准确验证:使用SileroVAD进行更准确的验证。SileroVAD基于深度学习模型,能更精确地区分语音与非语音时段,提高语音活动检测的准确性。转录模型:采用Faster_Whisper进行即时转录。Faster_Whisper是一个高效的语音转文本模型,支持GPU加速,能大幅提升转录速度,确保语音内容能实时转换为文本。唤醒词检测:支持使用Porcupine或OpenWakeWord进行唤醒词检测。能识别特定的唤醒词,激活系统,使设备能在待机状态下被唤醒并开始工作。
Github仓库:https://github.com/KoljaB/RealtimeSTT
智能设备控制:通过语音命令控制家中的智能设备,如灯光、窗帘、空调等,提升生活的便捷性。智能客服:在企业客服场景中,语音助手可以实时识别客户的问题并提供相应的解答,提高客服效率和客户满意度。会议转写:在会议或讲座中,RealtimeSTT可以实时将语音转换为文本,便于后续整理和分析。多语言翻译:在多语言会议中,RealtimeSTT可以实时将发言者的语音翻译成其他语言,提高沟通效率。实时字幕:为听力障碍者提供实时字幕,增强沟通的无障碍性。

AI与创造力相遇的未来 GPT 中心

适用于个人娱乐、学习、工作等场景
连接Spotify帐户并创建播放列表
语言学习工具
推荐书籍
将照片转换成辛普森风格的艺术作品
发现新的兴趣爱好
提供各种AI工具API
https://www.gpthub.best
小编发现GptHub.best网站非常受用户欢迎,请访问GptHub.best网址入口试用。
Step R-mini(全称Step Reasoner mini)是阶跃星辰推出的推理模型, 是 Step 系列模型家族的首个推理模型,擅长主动规划、尝试和反思,基于慢思考和反复验证的逻辑机制,为用户提供准确可靠的回复。模型既擅长解决逻辑推理、代码和数学等复杂问题,也能兼顾文学创作等通用领域。Step R-mini在数学基准测试和代码任务上表现优异,实现了文理兼修。Step R-mini坚持 Scaling Law 原则,包括强化学习、数据质量、测试时计算和模型规模的扩展。
数学问题:构建合理的推理链,对复杂数学问题进行规划和逐步求解。在解答奥数难题时,枚举不同解法方案进行交叉验证。处理几何题目时,主动用画草图构建深度思考的内容介质,全面严谨地分析题目需求,选择最佳解题公式,基于多次自我追问确定是否有没被考虑到的因素。逻辑推理:自主尝试多种解题思路,在得到初步答案后,自我反问尝试有没有其他可能性,确保枚举出所有效果良好的解决方案,在交卷前检查有无遗漏,提供全面且准确的推理结果。代码解答:基于长推理链正确解答难度较高的算法题,如 LeetCode 技术平台上评级为“Hard”的题目。还能处理复杂的开发需求,逐步分析用户需求和意图,构建代码逻辑,在代码写作中穿插对当前代码片段的分析和验证,最终给出可执行的代码。文学创作:深入理解用户的表达需求,分析创作主题、文学题材要求,思考创作角度、描绘的景物、修辞手法、内容结构等,赋予事物人类情感层面的象征意义,并增加个性化、创新的表达风格,像个“追求完美”的创作者。
坚持 Scaling Law 原则:Scaling Reinforcement Learning:从模仿学习到强化学习,从人类偏好到环境反馈,用强化学习为模型迭代的核心训练阶段。Scaling Data Quality:在确保数据质量的前提下,持续扩大数据分布与规模,为强化学习训练提供保障。Scaling Test-Time Compute:兼顾测试阶段的计算扩展,System 2 的范式让 Step-Reasoner mini 能在极复杂任务推理上,达到 50,000 tokens 进行深度思考。Scaling Model Size:坚持模型规模扩展是 System-2 的核心,正在开发更智能、更通用、综合能力更强的 Step Reasoner 推理模型。文理兼修:在 AIME 和 Math 等数学基准测试上,成绩超过 o1-preview,比肩 OpenAI o1-mini。在 LiveCodeBench 代码任务上,效果优于 o1-preview。大部分推理模型难以兼顾文理科双方向能力, Step R-mini 基于大规模的强化学习训练,用 On-Policy(同策略)强化学习算法,实现“文理兼修”。
项目官网:Step R-mini
逻辑推理:在处理逻辑推理任务时,Step R-mini自主进行多种解题思路的尝试,在得到初步答案后,自我反问尝试有没有其他可能性,确保枚举出所有效果良好的解决方案,并在交卷前检查有无遗漏。
教育辅导:辅助学生解答数学难题、编程困惑,提供解题思路和代码示例,助力学习提升。科研助力:帮助科研人员进行逻辑推理、数据分析,整合跨学科知识,推动科研项目进展。企业办公:协助程序员高效开发代码,为管理者提供商业决策的逻辑分析和建议,优化办公流程。文学创作:激发文化创意工作者的灵感,提供个性化、创新的文学创作方案,丰富作品内涵。翻译服务:满足高质量翻译需求,精准转换语言,促进文化交流与传播。