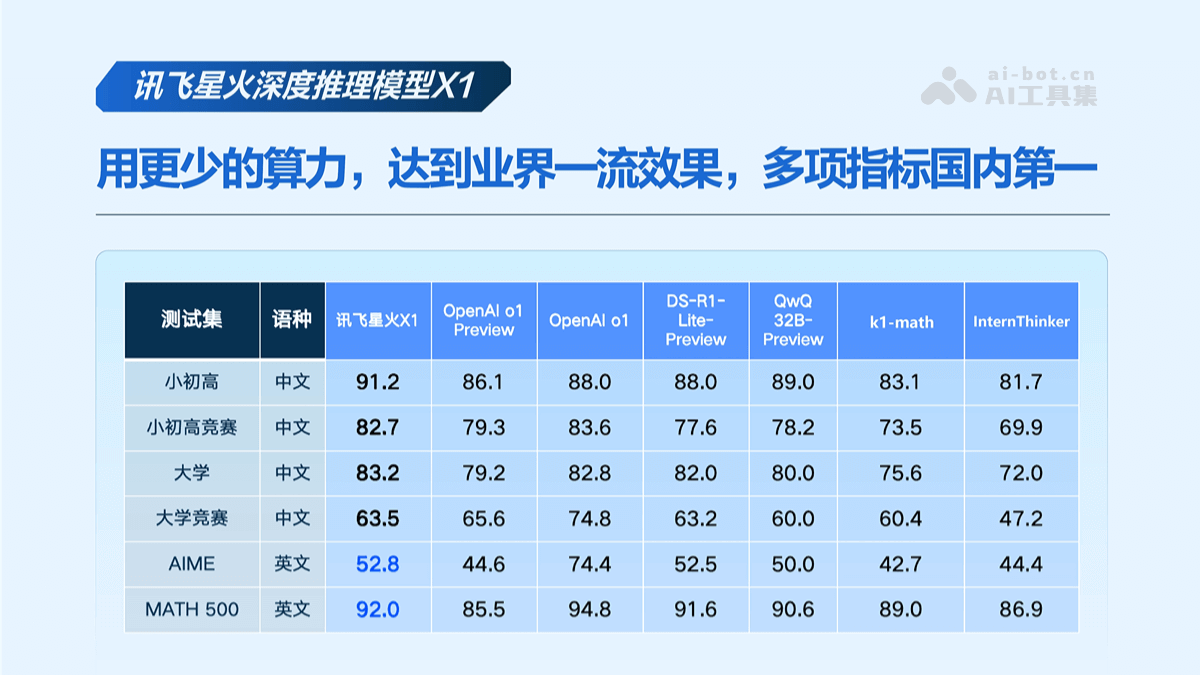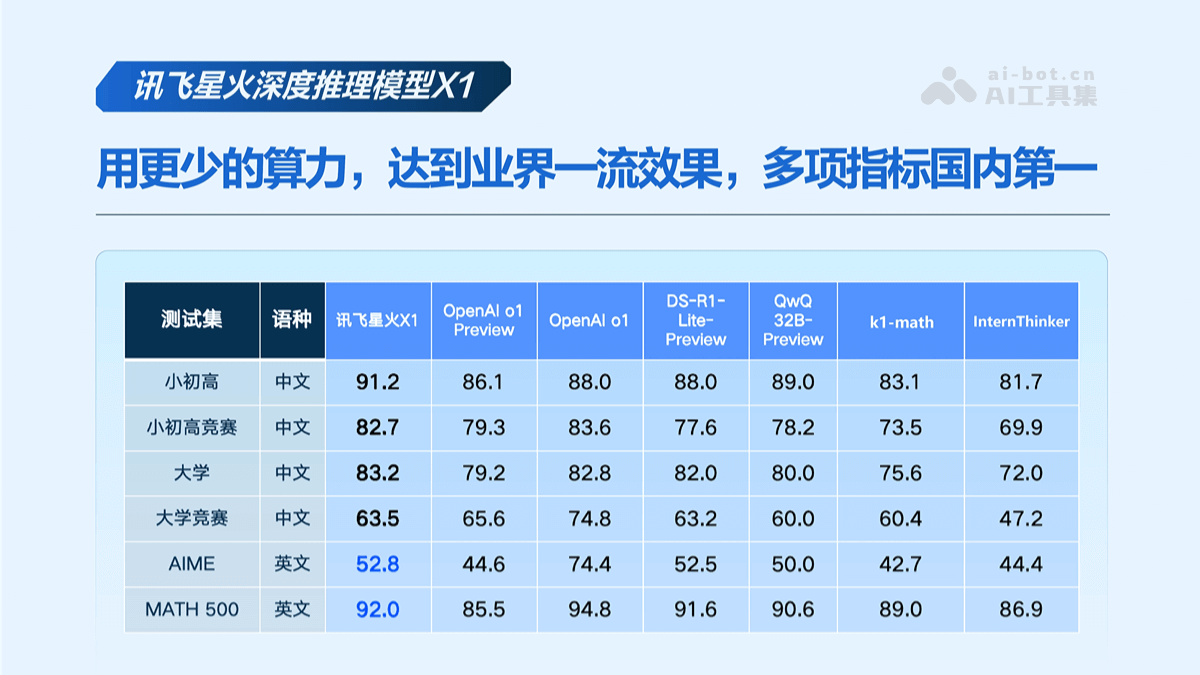

MiniMax-01是什么
MiniMax-01是MiniMax推出的全新系列模型,包含基础语言大模型MiniMax-Text-01和视觉多模态大模型MiniMax-VL-01。MiniMax-01首次大规模实现线性注意力机制,打破传统Transformer架构限制,参数量达4560亿,单次激活459亿,性能比肩海外顶尖模型,能高效处理全球最长400万token上下文。MiniMax-01系列模型以极致性价比提供API服务,标准定价低,且在长文任务、多模态理解等多方面表现优异。
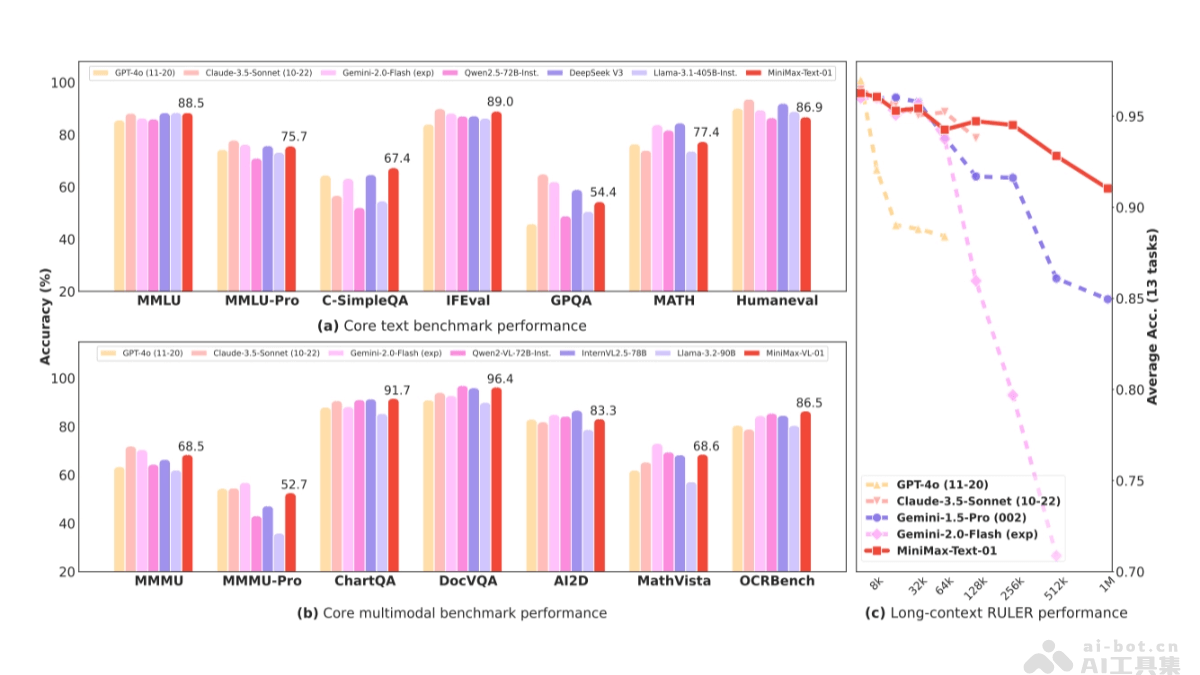
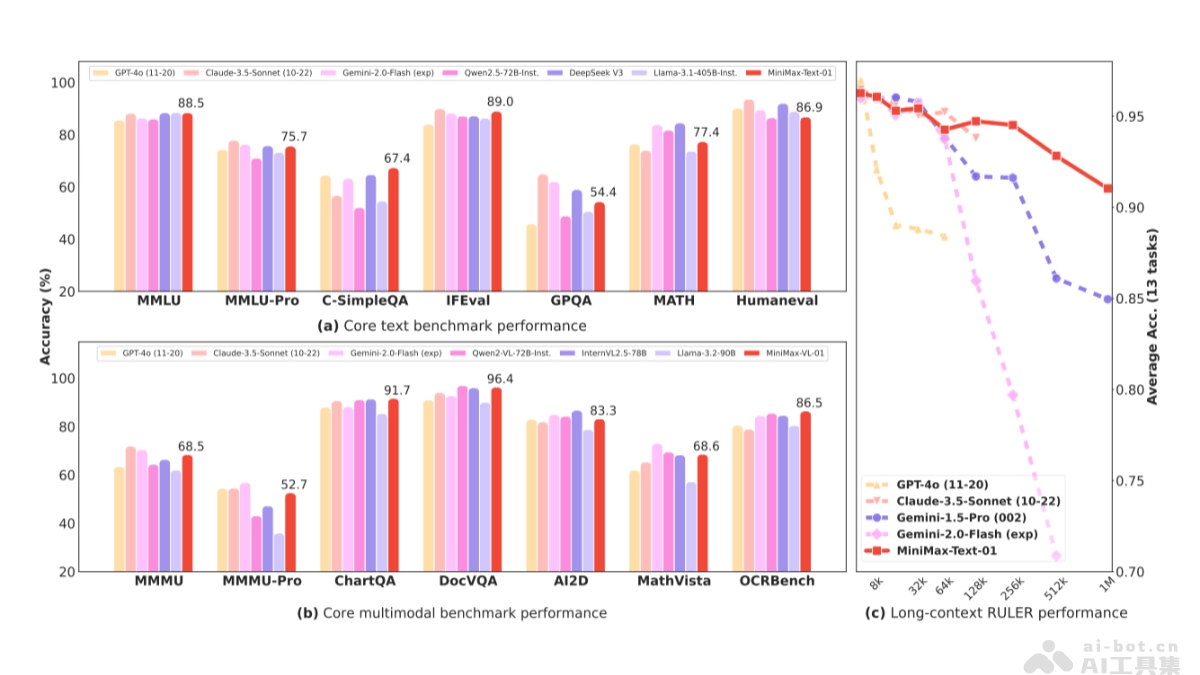
MiniMax-01的性能表现
参数量与激活量:模型参数量高达4560亿,单次激活459亿,综合性能比肩海外顶尖模型。超长上下文处理能力:够高效处理全球最长400万token的上下文,是GPT-4o的32倍,Claude-3.5-Sonnet的20倍。主流测评结果:在大多数任务上追平海外公认最先进的两个模型,GPT-4o-1120以及Claude-3.5-Sonnet-1022。长文任务优势:在长文任务上,性能衰减最慢,显著优于Google的Gemini模型。处理长输入效率:接近线性复杂度,与其他全球顶尖模型相比具有明显优势。
MiniMax-01的主要功能
语言理解与生成:文本摘要:能够从长篇文章中提炼关键信息,生成简洁准确的摘要。翻译:实现不同语言间的准确转换,保持语义的完整性和准确性。问答:基于给定文本或自身知识回答问题。封闭问答针对特定文本内容,开放域问答涵盖更广泛的知识范围。多模态理解:图文匹配:判断文字是否准确描述了图片内容,用于图像标注、内容审核等场景。图像描述生成:根据图片生成通顺、准确的描述文本,帮助理解图像中的元素及布局关系。视觉问答:结合图片信息回答涉及视觉内容的问题。长上下文处理:高效处理长达400万token的上下文,满足专业书籍阅读、编程项目协助、长篇文档分析等实际需求,为复杂Agent系统的构建提供基础能力。
MiniMax-01的技术原理
线性注意力机制核心思想:将传统Transformer中计算量大的自注意力机制,基于数学技巧转化为线性复杂度,让模型能高效处理长序列。Lightning Attention:线性注意力的一种优化实现,用分块技术,将注意力计算分为块内和块间计算,块内用左乘积,块间用右乘积,保持整体计算复杂度线性,提高处理长序列的效率。混合架构架构设计:模型中每8层有7层使用线性注意力,1层用传统的SoftMax注意力。结合线性注意力的高效性和SoftMax注意力的优势,尤其在处理长上下文任务时表现出色。性能验证:证明混合架构在长上下文任务中的性能和效率优势,例如在长上下文检索任务中,随着输入长度增加,MiniMax-Text-01性能衰减最慢。模型优化与训练MoE优化:为减少MoE架构中通信开销,推出令牌分组重叠方案,通信与不同专家组的令牌处理重叠,减少等待时间。引入EP-ETP重叠策略,提高资源利用率,减少通信开销,提升训练效率。长上下文优化:采用“数据打包”技术,减少计算浪费。设计Varlen Ring Attention算法,直接对打包后的序列应用环形注意力计算,避免过度填充。提出LASP+算法,优化线性注意力序列并行计算流程,实现完全并行化计算,提高系统效率。lightning attention推理优化:基于批量内核融合、分离预填充和解码执行、多级填充、strided batched matmul扩展等策略,减少内存访问操作,提高推理速度。
MiniMax-01的项目地址
项目官网:MiniMax开放平台:https://www.minimaxi.comMiniMax开放平台海外版:https://www.minimaxi.com/enGitHub仓库:https://github.com/MiniMax-AI技术论文:https://filecdn.minimax.chat/_Arxiv_MiniMax_01
MiniMax-01的API定价
MiniMax-Text-01:强大的长文处理能力,上下文长度1000k,输入0.001元/千token, 输出0.008元/千token。MiniMax-VL-01:强大的视觉理解能力,上下文长度1000k,输入0.001元/千token, 输出0.008元/千token。
MiniMax-01的应用场景
企业用户:涵盖内容创作者、市场营销人员、客服团队、技术团队和知识管理人员,提高内容创作、营销效果、客户满意度、项目开发和知识共享的效率。教育工作者和学生:教师生成教学材料,学生借助它进行学习辅助,提升教学和学习质量。创意工作者:作家、诗人、歌词创作者、设计师和艺术家,获取创作灵感,辅助创意写作和艺术设计,激发创意潜能。研究人员和学者:适用于处理学术论文、进行文献综述,提高科研工作的效率和深度。开发者和工程师:自然语言处理开发者、多模态应用开发者和系统集成工程师,开发定制化应用,提升系统智能水平。